Bu yazıda
büyük veri (big data), veri kazıma (data mining), veri bilimi (data science), düzenek öğrenmesi (machine learning), yapay us (artificial intelligence), yapay sinir ağları (artificial neural networks), iş usu (business intelligence) gibi kavramlar açıklanmaktadır. Bunların tanımlarının verilmesi dışında aralarındaki ayrımlar üzerinde durulmaktadır.
Büyük Veri
Bir kavram olarak
büyük veri (big data), kolayca işlenemeyecek ölçüde büyük veri anlamına gelir. Burada verinin çok büyük olması değil, özel süreçlere sokulmadıkça işlenemeyecek ölçüde büyük olması anlamı bulunmaktadır.
Dağıtık Sırtlı Düzeni (Distributed File System)
Verinin büyük olmasının en önemli sonuçlarından biri, verinin tek bir bilgisayar ya da teker (disk) biriminde saklanamasıdır. Bunun için
dağıtık sırtlı düzeni (distributed file system) adı verilen bir yapı kullanılır. Buna göre aynı ağda olmak koşuluyla, birden çok teker tek bir birim gibi gösterilir. Burada amaç verinin bulunduğu konumdan taşınmadan, olduğu yerde kullanılmasıdır.
Özkaynak Oylaşması (Resource Negotiation)
Bir başka büyük veri konusu da
özkaynak oylaşması (resource negotiation) konusudur. Verinin büyük olması, saklanması ve erişilmesi sorunu dışında işlenmesi için de büyük kaynakların gerektirmesi gibi bir durum ortaya çıkarır. O yüzden ayrı bilgisayarlar alınsa da veriden bir sonuç alma işlemi için yeterli donanım bulunamaz. O yüzden de var olan, bir biçimde çalışan bilgisayarların kullanılmayan güçleri ve zamanları kullanılır. Örneğin, olağan durumlarda bir veritabanı sunucusunun üzerinde çalıştığı bilgisayarın, daha çok gündüzleri çalışılan kurumlarda, geceleri çok kullanılmaması nedeniye büyük veri için kullanılması gerekir. Ancak bu kez de bir çok sunucunun kaynaklarının yönetilmesi gibi bir sorun ortaya çıkar. İşte bu nedenle özkaynak oylaşması (resource negotiation) yazılımları kullanılır. Bunlar hangi bilgisayarın ne ölçüde boş olduğunu, diri olarak gözlerler ve ilişkin olarak az işli olan donanıma belli görevler vererek onların büyük veri işleme için kullanılmasını sağlarlar.
Eşleme-İndirgeme (Map-Reduce)
Verinin büyüklüğü yanısıra türlülüğü de bir sorun olarak ortaya çıkar. Türlü veritabanı (database), sırtlı (file) ya da sunum (service) kaynağından veri gelebilir. Bu veriler birbiriyle uyumsuz olabilir; o yüzden dönüştürülemeleri gerekir. Verilerin gereksiz bilgileri olabilir, bunların ayıklanması gerekir. Verilerde eksiklikler olabilir. Veri kaynağında girilmese de belli olan bilgi, birleştirme durumunda belirsiz olabilir. Kaynaklardan gelen verinin kullanılacak duruma getirilmesine
eşleme (map) adı verilir. Bu adın verilmesinin nedeni kaynaktaki veri ile kullanılacak veri arasında bir eşleme yapılmasıdır. Eşleme sonrasında verilerin kullanılacak biçimde özetlenmesine de
indirgeme (reduce) adı verilir. Örneğin gelen çok sayıda satış bilgisinden toplam satışı bulmak indirgemedir. Genellikle eşleme (map) ve indirgeme (reduce) işlemi ayrı süreçlerde yapılır. Büyük veri yazılımları, önce eşlemeleri çalıştırır. Veri kullanılacak duruma geldikçe de indirgeme süreçlerini işletir. Veri işlemenin bu iki süreçi çoğunlukla
eşleme-indirgeme (map-reduce) olarak adlandırılır.
Veri Kazıma (Data Mining) ve Veri Bilimi (Data Science)
Verilerin belli kaynaklardan sökülme (extraction) işlemine
veri kazıma (data mining) adı verilir. Burada verinin kolay erişilir olmadığı durumlar söz konudur. Başka bir deyişle, veri gizlidir ya da ortada olsa da çok verinin içinde yitik durumdadır. Buradaki verinin kullanılır duruma getirilmesine veri kazıma (data mining) adı verilir. Öte yandan veri bilimi (data science) ise verileri işleme ve sonuçlar çıkarma işlemine verilen addır. Verileri işlemek için en çok kullanılan yöntemler
sayımlama (statistics) bilimi içerisinde yer alır. Ancak veri bilimi yalnızca bu sayımlama bilimini değil
bilgisayım bilimi (computing science) konularını da kullanır. Örneğin
yapay us (artificial intelligence), özellikle de bunun alt dalı olan
düzenek öğrenmesi (machine learning) yararlanılan konulardandır. Bunun dışında veri bilimi ile sayımlama (statistics) arasındaki temel ayrım da, sayımlamanın daha çok verini işlenmesiyle ilgili bir uzbilim (mathematics) alt dalı olmasına karşın veri biliminin verinin elde edilmesi ve işlenmesi ile ilgili de olmasıdır. Veri bilimi, verinin bilimi olmaktan çok veri üzerinde bilim uygulamak anlamı taşır. Başka bir deyişle veri üzerinde uzbilim (mathematics), sayımlama (statistics) ya da bilgisayım (computing) bilimlerindeki kavramların uygulanmasıdır.
Yapay Us (Artificial Intelligence), Düzenek Öğrenmesi (Machine Learning) ve İş Usu (Business Intelligence)
Bilgisayar biliminin bir al dalı olan
yapay us (artificial intelligence), bilgisayarların insan zekasına benzer bir biçimde çalışmasını sağlamaktır. Bir ölçüde tüm bilgisayar bilimi yapay us gibi algılanabilse de yapay us gerçekte insanın düşünme yönteminin bilgisayara aktarılmasıdır. Bilgisayarın bir çok alanı düşünmekten çok bilgi işleme görevi görür. Akılla yapılıyor gibi görünen bir çok işlem aslında verilerin işlenmesi ve değerlendirilmesi sonucunda ortaya çıkar. Bir çok kez bilgisayar anlamak ve düşünmek yerine, çok sayıda işlemi hızlı yapabilmesi gücüne güvenerek sonuç üretir. Öte yandan yapay us ise bilgisayarın insan gibi düşünme becerisi edinmesi çabasıdır.
Yapay usun bir alt alanı
düzenek öğrenmesi (machine learning) konusudur. Bu kavram, verinin içinden anlamlı bilgiler edinilmesi sürecidir. Insanların kolayca yapabildiği gibi, karmaşık olarak görünen görüntü ya da verilerden sonuçlar üretilmesidir. Yapay us çok genel bir konu durumundayken düzenek öğrenmesi bunun bölümlerinden birisidir. Ancak öteki dallar çok elle tutulur, günlük yaşamda kullanılabilir bir işlev kazanamasalar da düzenek öğrenmesi bir çok kurumda sürekli kullanılır durumdadır. Başka bir deyişle öteki yapay us konuları gelecekle ilgili bilimsel çalışmalar durumundayken düzenek öğrenmesi (machine learning) iş dünyasında bugün yoğun bir biçimde kullanılmaktadır. Düzenek öğrenmesindeki yöntemlerden birisinin adı
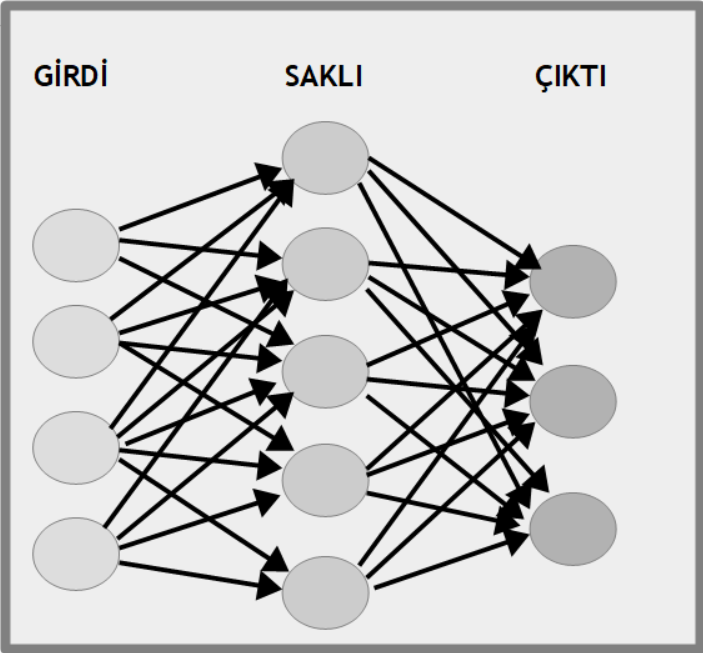
yapay sinir ağları (artificial neural networks) adını taşır. Düzenek öğrenmesi için kullanılan bu teknik, insanın sinir ağlarına benzediği düşünüldüğü için bu adı almıştır. Herhangi bir biyolojik benzerlik yoktur; tümüyle bilişimle ilgili bir konudur. Yapay us tekniklerin işletmelerde kullanılmasına
iş usu (business intelligence) adı verilir. Buradaki kavram, iş dünyasında karar vermek için bilgisayar biliminin kullanılmasıdır. Yapay us tekniklerinin bilinmesi yeterli olmaz, iş (business) kavramlarının da bilinmesi gereklidir. Öte yapay us, iş dünyasıyla doğrudan ilgili olmayan güdümbilim (cybernetic) ya da robotik (robotics) gibi alanlarda da kullanılır.
Bileşim, Kesişim, Ayrım
Yukarıda anlatılan kavramlar birbirlerinden tümüyle bağımsız değildir. Yaklaşık olarak aynı konu oldukları da söylenemez. Burada ayrımlar üzerinde durulmaktadır.
Veri Kazıma (Data Mining), Veri Bilimi (Data Science), Büyük Veri (Big Data)
Bir kaynakta veriler üzerinde özel bir işlem yapılmadan kullanılabilir durumdaysa
veri kazıma (data mining) gerekli değildir. Ancak temiz veri üzerinde veri bilimi (data science) doğrudan uygulanabilir. Öte yandan, veri kazıma ile sorunlu veriler düzeltildikten sonra üzerinde herhangi bir işlem yapılmayabilir. Bu durumda veri bilimi kullanılmıyor demektir. Üzerinde çalışılacak veri karmaşık ve sorunlu, ancak çok kaynak kullanımını gerektirecek düzeyde büyük olmayabilir. Örneğin tek bir kurumun verisi kullanılır durumda değilse veri kazıma yapılır ancak büyük veri işlemleri yapılmaz. Öte yandan büyük ölçüde veri son derece temiz durumda olabilir. Bu durumda veri kazıma olmaz ancak büyük veri kullanılır. Büyük veriden elde edilen veriler doğrudan bir yazanak (rapor) biçiminde kullanılıyorsa burada veri bilimine gerek yoktur. Öte yandan az bir veride bilimsel yöntemlerle sonuçlar alınabilir. Bu durumda veri bilimi var ama büyük veri yoktur. Çoğu durumda veri tek bilgisayarın kaldıramayacağı ölçüdedir ve büyük veri kullanılır. Çoğu durumda veri kullanılmaz durumdadır ve veri kazıma yapılır. Çoğu durumda bilisel yollarla sonuçlar çıkartılır ve veri bilimi kullanılır. Özetlenirse, çoğu durumda büyük veri, veri kazıma ve veri bilimi birlikte kullanılır.
Veri Bilimi (Data Science), Düzenek Öğrenmesi (Machine Learning) ve İş Usu (Business Intelligence)
Veri bilimi yaparken sayımlama (statistics) ve uzbilim (mathematics) tekniklerini kullandığı gibi düzenek öğrenmesi (machine learning) gibi yapay us (artificial intelligence) konularını da kullanılır. Öte yandan yapay us, veri bilimi dışında güdümbilim (cybernetic) ya da robotik (robotics) alanında da kullanılır. Veri bilimi bu anlamıyla sayımlama (statistics) ve uzbilim (mathmetics) ile bilgisayım biliminin kesişimi olarak işlev görür. İş dünyasında yapay usun kullanılmasına
iş usu (business intelligence) adı verilir. Öte yandan iş usu, iş çözümleme (business analysis) alanının bir alt dalı olarak işlev görür. Başka bir deyişle iş usu, yapay us ile iş çözümlemenin kesişim kümesindedir.
Biraz Daha Sözcük
Yukarıdaki ana konular dışında, bu tür konularla ilişkili olarak bilinmesi gereken bir çok kavram bulunmaktadır. Bunların çoğu yukarıdaki anlatılanların alt dalı ya da yan koludur. Bunlardan
veri çözümleme (data analysis), veri üzerinde yapılan her tür temizleme, dönüştürme ve modelleme işlemimin adıdır. Dolayısıyla veri kazıma, veri çözümlemenin bir dalı olarak düşünülebilir. Bir başka ilişkili kavram olarak
veri ambarı (data warehouse) sayılabilir. Verilerin tümünü ya da çoğunu içeren bütüne veri ambarı adı verilir. Çoğunlukla veri kazıma verileri türlü kaynaklardan veri ambarına taşır. Bir kurumdaki tüm veritabanı (database) ve sırtlık (file) birimlerinde bulunan veriler belli zaman aralıklarıyla toplu bir ortama aktarılırlar. Verilerden bir sonuç üretilmesine
yazanak (report) adı verilir. Ancak diri olarak olarak verilerin görülebildiği ortamlara
ön göğüs (dashboard) adı verilir.
Veri bilimiyle ilgili sözcükler arasında;
veriyle boğuşma (data mungling),
sınıflandırma (classification),
salkımlama (clustering),
gerileme (regression),
görselleştirme (visualization) gibi kavramlar bulunur. Bunlardan veriyle boğuşma (data mungling), bozuk ya da düzensiz verinin düzeltilmesidir. Birbirine yakın iki kavramdan birisi olan sınıflandırma (classification), verilerine önceden belli olan sınıflardan hangisine girdiğini bulmaktır. Öte yandan salkımlama (clustering) ise baştan herhangi bir sınıfın belli olmadığı durumlarda, sınıfların verilere bakılarak belirlenmesidir. Kavramlardan gerileme (regression), dağınık gibi görünen veriden belli doğru (line) ya da eğri (curve) biçiminde bir uzbilimsel bağıntı bulmaya denir. Veri bilimi açısından görselleştirme (visualization) verinin çizgeleme (graphics) ya da çizelgeler (charts) biçiminde gösterilmesidir.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning
Bu yazıda
büyük veri (big data),
veri kazıma (data mining),
veri bilimi (data science),
düzenek öğrenmesi (machine learning),
yapay us (artificial intelligence),
yapay sinir ağları (artificial neural networks),
iş usu (business intelligence) gibi alanlarda kullanılan programlama dilleri ve diller dışında bilinmesi gerekenler anlatılmaktadır.
Hangi Konuları Bilmeli?
Her ne denli
veri bilimi (data science) ve
yapay us (artificial intelligence) yakın konular gibi görünse de, çoğu kez bir arada kullanılsa da bir çok durumda birisinde çalışılıp ötekisinde az etkinlik göstermek olanaklıdır. Bu nedenle veri bilimi için önerilen dillerle yapay us için önerilen diller aynı olmayabilir. Bir başka konu da veri bilimi ya da yapay us için kullanılmasa da bu alanlarda etkinlik gösterenlerin bilmesi gereken diller ve konular bulunmaktadır. Örneğin veri bilimi için öncelikle verinin elde edilmesi gerekir. Dolayısıyla veri erişimi ilgili dillerin bilinmesi gerekir. İşlenen verinin ne olduğunun da bilinmesi gerekir. İş dünyası ya da bilimsel verilerin kendisi üzerine de bilgili olunması gerekir.
Python
En yaygın kullanılan veri bilimi dilleri arasında en çok sözü edilenlerden birisi
Python dilidir. Python dili, veri bilimi ve yapay us konusunda çok varlıklı betiklik (library) içeren, genel amaçlı olan neredeyse tek dildir. Bunun dışındakiler ya genel programlama dillerdir ve veri bilimi ile yapay us için pek çok destek içeremezler ya da veri bilimi ile yapay us için destek içerirler ama genel amaçlı, her yerde kullanılacak durumda değildirler.
Python dili, bir çok dilde çok sayıda satırdan oluşan kod parçalarıyla yapılan bir işi bir veya iki satırda yazabilmektedir. Bu nedenle asıl işi yazılım geliştirme olmayan, karmaşık geliştirme yöntemlerini bilmesi gerekmeyen kişiler için çok büyük kolaylık sağlamaktadır. Bu nedenle yazılım mühendisliği ya da bilgisayar programlama gibi alanlar eğitim görmeyen, geçmişinde bilim, matematik ya da finans olanları için Python son derece geçerli bir seçenektir. Öte yandan, yazılım geliştirmeyle ilgili bir mesleği olanlar için de Python; gelişmiş araçları, kullanmak istenirse desteklemektedir. Başka bir deyişle, nesneye yönelik izlendirme (object-oriented programming) gibi tekniklerle geliştirme yapmak Pyhton dilinde olanaklıdır. Ancak, işlevsel izlendirme (function programming) yöntemini yeğleyenler için de kolay bir geliştirme seçeneği de sunmaktadır. Bu nedenle veri bilimi ve yapay us için son derece uygun bir seçenek olarak ortaya çıkmaktadır.
R
Bilindik yazılım geliştirme dillerinden olmasa da
R dili de veri bilimi ve yapay us alanında yaygın kullanılır. Gerçekte R, uzbilim (matematik), özellikle de sayımbilim (statistics) alanında kullanılma amacıyla üretilmiştir. Ancak veri bilimi ve yapay us için çok büyük desteği olduğu için bu alanlarda da kullanılır. Sonuç olarak söz konusu alanlarda matematik kullanmadan sonuç üretmeye olanak yoktur. Ücretli bir program olan
MATLAB,
SAS ve
SPSS gibi çevrelerin dilleri de yaygın kullanılmaktadır. Ancak edinilmeleri güç, ücretsiz olarak çalışılması pek olanaklı olmayan dillerdir. R açık kaynaklıdır. Herkes indirebilir ve en gelişmiş özellikleriyle kullanmaya başlayabilir. R öğrenenlerin MATLAB, SAS ve SPSS gibi özel ürünleri kullanabilmesi kolaydır, çoğu durumda son derece benzer biçimde çalışırlar.
R dilinin en büyük üstünlüğü, bir geliştirme dili olmanın ötesinde, doğrudan kullanılabilecek bir uygulama (application) olmasıdır. Başka bir deyişle dil, geliştirme ortamı, geliştirilen uygulamanın çalıştırılması tek bir çevrede gerçekleştirilmektedir. Bu anlamıyla MATLAB gibi bir uygulama olarak kullanılabilir. Dahası, herhangi bir geliştirme yapmadan da yalnızca çevrenin desteklediği özelliklerle sonuç üretmek olanaklıdır. Örneğin bir tablodaki verileri bir çizelge (chart) olarak görmek için geliştirme yapmaya gerek yoktur. Bu özelliği nedeniyle geliştirme yapmaya yavaş yavaş geçmek için de iyi bir araç olarak görülebilir.
Uzbilim (Mathematics) ve Sayımbilim (Statistics)
Bir çok alanla ilişkili olduğu gibi veri bilimi ve yapay us konuları
uzbilim (mathematics) ve
sayımbilim (statistics) konularıyla da doğrudan ilgilidir. Bir çok kişi için veri bilimi, sayımbilime verilmiş yeni bir addan başka bir şey değildir. Dolayısıyla matematik ya da istatistik bilmeden veri bilimi yapmaya olanak yoktur. Öte yandan, veri bilimi ve yapay us için gereken matematik, bilim, mühendislik ve finans alanında eğitim alanlar için çoktan öğrenilmiş durumda olabilir. Ancak yine de üzerinden geçilerek dinçleştirme yapılmasında yarar bulunur. Söz konusu alanlarda eğitim almayanlar ya da eğitim almasına karşın bilgileri diri durumda olmayanlar, özellikle sayımbilim konusunu iyi biçimde öğrenme durumundadırlar.
SQL, NoSQL, XML, JSON, CSV, Büyük Veri (Big Data)
Veri bilimi ile ilgili çalışacak kişileri
SQL ve
NoSQL gibi veritabanı (database) konularını iyi bilmesi gerekir. Verilerin çoğu bu ortamlarda bulunur ve bunları almak çoğu kez veri bilimcinin işidir. Dahası, SQL dili veriye erişmek için kullanıldığı gibi kendisi de bir veri bilimi dilidir. Dolayısıyla Pyhton, R ya da başka herhangi bir dil ya da çevre kullanılsa da başta SQL olmak üzere veritabanı dilleri bilinmelidir. Veriyi ilgili XML, JSON ve CSV biçimlendirmeleri ve büyük veri (big data) konuları, en azından temel düzeyde bilinmelidir.
Web, HTML, CSS, JavaScript
Veri bilimi genellikşe arka uç (back-end) alanına girmektedir. Ancak verilen bir kesimi SQL veya NoSQL gibi veritabanlarından gelmez. Çoğu örün (web) alanından gelir. Bu nedenle
HTTP,
HTML,
CSS ve
JavaScript gibi örün (web) ile ilgili dillerin bilinmesi yararlı olur. Bu dillerin bir önemi de veri bilimiyle elde edilen verilenin sunulurken kullanılmalarıdır. Dolayısıyla çok koşul olmasa da örün programlama bilinmesi çok yararlıdır. Hemen her projenin Genelağ (Internet) ile bir ilgisi vardır ve herhangi bir alanda çalışanlar bu konuları bilmelidir.
C/C++
Veri bilimi için kullanılan bir başka önemli seçenek de
C/C++ dilidir. Python ve R veri bilimi için çok daha uygun ve kolay olmalarına karşın C/C++ dillerinin belli alanlarda üstünlükleri bulunmaktadır. C/C++ dillerinin en önemli artısı hızıdır. Çok çabuk sonuç döndürülmesi gereken alanlarda C/C++ kullanılabilmektedir. C/C++ dilinin kullanılmasının bir nedeni de geçmişten gelen betikliklerdir. Python ve R olmadan önce de C/C++ vardı ve bir çok kurumda bilim, finans ve mühendislikle ilgili işler bu dille yapılmaktaydı. Dolayısıyla veri bilimi için de buradan sürdürmeye ve C/C++ ile geliştirme yapılmaya karar verilmektedir. C/C++ dili, bilimsel alanda çok yaygın olarak kullanılmaktadır. Örneğin veri yapıları ve algoritmalar, bilimsel bilgisayım, uygulamalı matematik gibi konularda C/C++ ile çok sayıda eğitim ve yayın vardır. Öte yandan, C/C++ gibi diller bu alanda algoritmaların anlaşılması ve gerçekleştirilmesiyle ilgilidir. Pyhton gibi dillerde ise algoritmanın yalnızca kullanılması veya kullanılacak kadar anlaşılması gereklidir. Başka bir deyişle Python yalnızca sonuçlarla ilgilenir. Neyin nasıl bulunduğuyla çok fazla ilgilenmez. Ancak C/C++ dilinde gerçekten işlerin nasıl çalıştığına yönelik çalışmalar yapılır. Veri bilimi ya da yapay us ile akademik çalışma yapanlar için C/C++ en önemli seçeneklerden birisidir. Ancak akademik çalışma yapmayan ya da hızlı çalışması için geliştirme kolaylığından vazgeçmeyecek olanlar için C/C++ daha az çekici olabilir.
Veri Yapıları & Algoritmalar (Data Structures & Algoritmalar) ve Bilgisayım Bilimi (Computer Science)
Veri bilimi ve yapay us konusunun bir ucu veri (data) ve bir ucu geliştirme (developement) olsa da; bir ucu bilgisayım bilimi (computing science) alanıyla ilgilidir. Gerçekte yapay us, bilgisayım biliminin bir alt dalıdır. Veri bilimi için çok derin bir bilgisayım bilimi tabanı gerekmese de; veri yapıları ve algoritmalar konusunu bilmeyenler için yapay us gibi konuları anlamak kimi durumda çetin olabilmektedir. Örneğin
karar ağacı (decision tree) konusunun anlamak, ağaç (tree) konusunu bilen biri için kolaydır. Temel bilgileri bilmeyenlerin bir de bilgisayım biliminde belli bir düzeyde bilgi edinmeleri gerekir. Bilgisayım biliminin bir çok alanı, örneğin
sayısal çözümleme(numerical analysis) ve
çizgisel izlendirme(linear programing) gibi alanlar doğrudan veri bilimin konusudur.
İş Çözümleme (Business Analysis) ve Kurumsal Uygulamalar (Enterprise Applications)
Doğrudan programlama ile ilgili olmasa da veri bilimi ya da yapay us üzerinde çalışanların bilmesi gereken konulardan birisi de
iş çözümleme(business analysis) konusudur. Üzerinde çalıştığı veriyi bilmeyen bir kişinin başarı olasılığı düşüktür. Bilim alanları dışında yazılım geliştirmenin en önemli alanı iş dünyasıdır. Yapay us, iş ile ilgili alanlarda uygulanınca
iş usu(business intelligence) adını taşır. Dolayısıyla veri bilimi veya iş usu ile ilgilenenlerin kurumsal uygulamalar (enterprise applications) konusunda bilgili olmaları gerekir. Muhasebe, satış, satın alma, finans, stok, üretim, elektronik ticaret gibi konuları bilmeyen kişilerin bu uygulamaların ürettiği veriyi anlaması çok güçtür.
İzdüşü Yönetimi (Project Management) ve Geliştirme İşlemleri (Development Operations)
Bir başka bilinmesi gereken konu de
izdüşü yönetimi(project management) ve
geliştirme işlemleri(development operations) konusudur. Bir çok kişi veri bilimi alanının yalnızca akademide kullanılan bir bilim dalı ve yapay us konusunun de bilgisayım bilimiyle ilgili bir alt konu olduğunu düşünse de bu alanlarda yapılan iş, yazılım geliştirme (software development) etkinliğidir. Bu alanların bilimin konusu olması bu gerçeği değiştirmez. Veri bilimci ya da yapay usçu, kuramsal konuları bilen birisi değil geliştirme yapan sonuç üreten bir yazılım geliştiricisidir. Öteki yazılım geliştiricilerden ayrımı, insanların doğrudan kullanacağı bir izlence (program) üretmek yerine art alanda çalışan, yalnızca belirleyici durumda olan kişilerin kullanabileceği sonuçlar üreten yazılımlar geliştirmesidir. Ancak sonuç olarak bu da bir yazılım geliştirme alandır. Bilimi kullanan bir yazılım geliştirme etkinliğidir. O yüzden yazılım için izdüşü yönetimini de geliştirme işlemlerini de bilmesi gerekir.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning
Bu yazıda Gözetimli Öğrenme (Supervised Learning) & Gözetimsiz Öğrenme (Unsupervised Learning), Sınıflandırma (Classification), Salkımlama (Clustering), Gerileme (Regression), Yoğunluk Kestirimi (Density Estimation), Boyutsallık İndirgemesi (Dimensionality Reduction), Değiştirgenli Algoritma (Parameteric Algorithm) & Değiştirgensiz Algoritma (Nonparameteric Algorithm) konularından bahsedilecektir
Düzenek Öğrenmesi (Machine Learning) Nedir?
Düzenek öğrenmesi((machine learning)) , özel bir yazılım geliştirme (software development) üretmeden, bir uygulama (application) ya da izlendirme (programming) yapmadan, var olan bir veriden sonuçlar çıkarma ve ileriye yönelik öngörülerde bulunmaktır. Genellikle büyük veri (big data) olarak adlandırılacak ölçüde geniş bir veri kümesi (data set) üzerinde sayımbilim (statistics) yöntemlerini kullanarak verinin niteliğini anlamak ve bundan sonuçlar üretmek anlamına gelir. Örneğin bir insanın ağırlığına ve boyuna bakarak cinsiyetini kestirmek, bir meyvenin ağırlığına ve oylumuna bakarak hangi meyve olduğunu bulmak düzenek öğrenmesidir (makine öğrenmesi). Bir öbek insanın ağırlığını ve boyunu vererek kadınlar, erkekler ya da çocuklar gibi öbekler bulunması ya da ağırlığı ve oylumu verilen meyvelerin kendi aralarında kategorilere ayrılması da bir düzenek öğrenmesidir. Bir insanın ağırlığı ve boyu arasındaki ilişkiyi bulmak, bir meyvenin ağırlığı ile oylumuna arasında nasıl bir bağıntı olduğunu bulmak da makine öğrenmesidir. Çünkü bir kez bağıntı bulunduktan sonra boyutlardan birisi verilince ötekisini bulmak olanaklı olur.
Gözetimli Öğrenme (Supervised Learning) & Gözetimsiz Öğrenme (Unsupervised Learning)
Düzenek öğrenmesi için en temel ayrım
gözetimli öğrenme(supervised learning) ve
gözetimsiz öğrenme(unsupervised learning) biçimindedir. Burada
gözetim, öğrenme sürecine önceden bir takım bilgiler verilmesi anlamına gelir.
Gözetimli Öğrenme (Supervised Learning)
Gözetimli öğrenme yöntemlerinden önce kimi bilgiler verilir ve öğrenme işlemi bu verileri kullanılarak yapılır. Örneğin bir insan öbeğinde erkeklerin ve kadınların ağırlık ve boy ortalamaları verilip, cinsiyeti bilinmeyen bir insanın ağırlığı ve boyu verildiğinde erkek mi kadın mı olduğunu kestirmek ya da hangisinden olma olasılığının ne olduğunu bulmak gözetimli öğrenme türüne girer. Çünkü bu teknikte öncelikle erkek ve kadınlara ilişkin ortalamalar baştan verilmiştir. Burada gözetim, öğrenme sürecinde insanın katkısı anlamı taşır. Başka bir deyişle düzenek tümüyle bağımsız değildir.
Gözetimsiz Öğrenme (Unsupervised Learning)
Gözetimsiz öğrenme ise herhangi bir ön bilgi vermeden, doğrudan verileri sağlayıp sonuçlar alınmasıdır. Örneğin bir çok meyvenin ağırlık ve oylumunun bilindiğini varsayalım. Bu meyveler arasında kaç tür meyve olduğunu bulmak istenirse bu gözetimsiz öğrenmedir. Çünkü baştan meyvelerin neler olduğu ya da ağırlık ve boylarının ne olduğu bildirilmemiştir. Doğallıkla, gözetimsiz öğrenmede de bir kaç değiştirgen (parameter) verilebilir. Ancak bunlar verinin kendisiyle değil, öğrenme sürecinin nasıl işleyeceğiyle ilgili bilgilerdir.
Düzenek Öğrenmesi Konuları
Düzenek öğrenmesi konusunun uygulandığı bir çok alan bulunmaktadır. Ancak bunlardan bir kaçı hem çok yaygın olarak gerçekleştirilmektedir hem de çok yararlı, büyük ölçüde doğru sonuçlar üretmektedir. Bu uygulamalar birbirinden bağımsız olsalar da ortak bir çok teknik kullanırlar. Dahası, kimi durumlarda aynı anda kimi zamanda veya birbiri ardından kullanılabilir.
Sınıflandırma (Classification)
Düzenek öğrenmesinin en bilinenleri arasında en önemli uygulamalardan birisi
sınıflandırma(classification) adını taşır. Önceden sağlanan bilgilere göre verilerin sınıflara ayrılmasıdır. Bu bir gözetimli öğrenme (supervised learning) konusudur. Öncelikle bir veri öbeğindeki her verinin hangi sınıfa girdiği bildirilir. Daha sonra başka veriler sağlanır ve bunların hangi sınıflara girdikleri bulunur. Örneğin öncelikle bir çok erkek ve kadının ağırlığı ve boyu verilir. Buradan bir erkek ve bir kadının ortalama hangi ağırlıkta ve boyda olduğu bulunur. Daha sonra yeni veriler sağlanır ve bunların kadın ve erkek olarak ayrılması istenir.
Salkımlama (Clustering)
Düzenek öğrenmesi konusundaki en önemli konulardan birisine de
salkımlara(clustering) adı verilir. Buna göre bir veri kümesi verilir ve bunların öbeklere ayrılması istenir. Bu öbeklerin her birine salkım (cluster) adı verilir. Burada salkımlar baştan belli değildir ve belli bir ilkeye göre bulunur. Salkımlar bir gözetimsiz öğrenmedir. Çünkü salkımlar önceden öğretilmemiştir. Her ne denli verilerin öbekleri verilmese de verileri öbeklere ayırmak için gerekli ölçütlerin verilmesi gerekebilir. Örneğin verilerin kaç salkıma ayrılacağı, ya da bir birine ne kadar yakın verilerin aynı saklımda sayılacağı bildirilmelidir. Örneğin ağırlığı ve oylumu verilen meyvelerin arasında kaç tür meyve olduğu bildirilebilir. Düzenek öğrenmesi bu salkım sayısına göre veriyi öbeklere ayırabilir.
Gerileme (Regression)
Bir veri kümesindeki verilerdeki boyut (dimension) değerleri arasında ilişkinin bulunmasına gerileme(regression) adı verilir. Örneğin bir kişinin boyu ile ağrılığı arasındaki ilişki, bir meyvenin ağırlığı ile oylumu arasındaki matematiksel bağıntı bulunabilir. Bu konuya gerileme (regression) adının verilmesinin nedeni, rasgele görünen verilerin bir bağıntıya yakınlaşmasıdır. Gerçekte bir bağıntı olduğu; ancak verilerin türlü nedenlere bu bağıntıdan saptığı düşünülür. Gerileme ile her verinin gerçek bağıntısı bulunmuş, yani bağıntıya geri dönülmüş olur. Bir kez bu bağıntı bulunduktan sonra artık bir boyutunun değeri ile verilen öğenin öteki boyutu bulunabilir. Örneğin boyu verilen kişinin ağırlığı, ağırlığı verilen meyvenin oylumu bulunabilir. Gerileme için aranan bağıntı en yalın biçimiyle bir çizgi (line) olabilir ki buna çizgisel gerileme(linear regression) adı verilir. Burada \(y=a+bx\) biçiminde bir bağıntıda a ve b katsayıları bulunur. Kimi bağıntılar bir dönüşüm (transformation) uygulanarak çizgisel duruma getirilebilir. Bu durumda önce dönüşüm uygulanır, çizgisel gerileme bulunur, sonra ters dönüşüm uygulanarak çizgisel olmayan bağıntı elde edilir.Yoğunluk Kestirimi (Density Estimation)
Bir veri kümesinde belli bir boyuttaki değerlerin belli bir aralıkta kaç tane olduğunu gösteren işleve yoğunluk işlevi (densiti function) adı verilir. Örneğin insanların 160 cm ile 180 cm arasında kaç kişi olduğunu gösterir. Ortalama boyun 170 cm, ölçün sapma (standard sapma) değeri de 20 cm olarak alınabilir. Bu görevi yapan, sayımbilim (statistics) ve olasılık (probabilty) alanında bir çok yoğunluk işlevi bulunur. Bunlardan en önemlisi
olağan dağılım(normal distribution) olağan dağılım adını alır. Düzenek öğrenmesi, yoğunluk işlevinin kestirilmesi ile ilgilidir. Tüm veriye bakmadan, kümeden alınan örnek (sample) verilere bakarak yoğunluk işlevinin kestirilmesidir. Yoğunluk işlevinin kestirilmesi, artık herhangi bir verinin belli bir aralıkta olma olsılığının bulunması anlamına gelir. Örneğin insanların boylarıın olağan dağılıma girdiği; ortalamanın ve ölçün sapma (standard deviation) değerinin ne olduğu yoğunluk kestirimiyle bulunursa bir kişinin 175 boyunda olma olasılığının kaç olduğu bulunabilir.
Boyutsallık İndirgemesi (Dimensionality Reduction)
Veri kümeleri çoğu kez bir çok boyutan oluşur. Örneğin insanın ağırlığı, boyu, yaşı, kaç kardeşi olduğu, kaç arkadaşı olduğu gibi bir çok veri bulunmaktadır. Ancak çoğu kez bu boyutlardan bir kesimi çok anlamlı değildir. Örneğin insanların ağırlığı ile kaç arkadaşı arasında bir ilişki yoktur. Kimi durumlarda kimi boyutlar kimilerinden daha önemli olabilir. Örneğin kişinin ağırlığı ile hem boyu hem yaşı ilgili olabilir. Ancak bunlardan bir ötekinden daha önemli olabilir. Boyutlar önemliden önemsize doğru sıralanabilir ve az önemli olanlar göz ardı edilebilir. Kimi zaman boyutlarda bir dönüşüm yapılınca yeni boyutlardan birisi çok daha önemli olabilir. İnsanlar boyutlardan hangisinin daha önemli olduğunu düşünerek ya da bilgilerine dayanarak bulabilir. Ama makineler için bunun bulunması için işlem yapılması gerekir. Boyutların önemsizlerinin belirlenip dışarıda tutulmasına
boyutsallık indirgemesi(dimensionality reduction) adı verilir. Kimi durumlarda boyutları indirgeme gerçek boyutlarda değil dönüşüm (transformation) uygulanmış verilerde yapılır. Bir veri kümesinde veriler döndürme (rotation) ve öteleme (translation) yapılmış durumda olabilir. Bu durumda boyutları çözümleme yanlış sonuç verir. Bu yüzden öncelikle verinin döndürmesiz ve ötelemesiz duruma getirilmesi gerekebilir. Bir çok durumda bu geri dönüştürme sonucunda oluşan boyutlar gerçek boyutlardan daha anlamlıdır. Boyutsallık indirgemesi bu geri dönüşmüş veriler için de söz konusudur.
Değiştirgenli Algoritma (Parameteric Algorithm) & Değiştirgensiz Algoritma (Nonparameteric Algorithm)
Düzenek öğrenmesinde kimi zaman aranan model bellidir. Örneğin gerileme (regression) bulma yöntemlerinde iki boyut arasında ilişkinin çizgisel (linear) olduğu baştan doğru olarak alınabilir. Buna göre \(y=a+bx\) biçiminde bir çizgide a ve b katsayıları aranır ve bunlar bulunabilir. İşte parametrelerin sayısı ve türünün belli olduğu düzenek öğrenmesi algoritmalarına değiştirgenli algoritma(parameteric algorithm) adı verilir. Ancak kimi durumlarda boyutlar arasında ilişki çizgisel olmayabilir. Örneğin eğri olabilir ve bu durumda işlev \(y=a+bx+cx^2\) olabilir. Ya da \(y=ae^{bx}\) biçiminde olabilir. Öte yandan, herhangi bir matematiksel bağıntı olmayabilir. Ya da bağıntı varsa da bulunması olanaksız ya da gereksiz olabilir. Düzenek öğrenmesi, belli matematiksel bağıntıları bulmadan yapılırsa değiştirgensiz algoritma(nonparameteric algorithm) adı verilir. Bu türde verinin boyutları arasında ilişki veya bağıntı bilinmez, yalnızca ilişkinin varlığı bilinir. Bu tür öğrenmeden nedenlere değil sonuçlara bakarak işlem yapılır.Yöntemler (Methods) ve Algoritmalar (Algorithms)
Düzenek öğrenmesi algoritmaları arasında çok bilinenleri aşağıdaki yer almaktadır. Bunların öğrenilmesi durumunda ötekiler üzerine de bilgi sahibi olunabilir. Çünkü öteki algoritmalar buradakilere benzer özellikler taşır ve aşağıdakileri öğrenmek için gerekli öngereksinimlerin bilinmesi ötekelilerin öğrenmesini de büyük ölçüde kolaylaştırır.
- Yapay Sinir Ağı (Artificial Neural Network)
- K-En Yakın Komşu (K-Nearest Neighbour)
- İlkesel Bileşen Çözümleme (Principal Component Analysis)
- Destek Yöney Düzenekleri (Suppor Vector Machines)
- Toy Bayesçi Sınıflayıcı (Naive Bayesian Classifier)
- Karar Ağacı (Decision Tree)
- Rasgele Orman (Random Forest)
- K-Bayağı Salkımlama (K-Means Clustering)
- Genetik Algoritmalar (Genetic Algorithms)
Pyhton dili kolay öğrenilmesi ve kullanılması gibi bir takım özellikleri nedeniyle bir çok geliştirici tarafından beğenilmektedir. Ancak veri bilimi ve yapay us gibi konularda çok beğenilmesinin nedeni bu özelliklerinden çok, geliştirme için bir çok betiklik (library) sunmasıdır.
Ölçün (Standard)
Python dilinin kendisinde bir çok işlem için son derece kullanışlı bir çok sınıf (class) ve işlev (function) bulunmaktadır. Yazılım geliştirme için gerekli veri yapıları ve algoritmalar (data structures and algorithms) konularındaki destek son derece geniştir. Dahası, öteki programlama dillerine göre bunların kullanımı son derece kolaydır.
Veri Türleri (Data Types)
Python dilinde bütün (integer) ve kayan (floating) sayı türleri, mantıksal (boolean) türler, sicim (string) türü dışında dizi ve öteki biriktiri (collection) türü veri yapıları da bulunmaktadır. Bunlardan dizelge (list), küme (set) ve sözlük (dict) / eşlem (map) gibi yapılar sayılabilir.
Sırtlı (File) ve Akımlar (Stream)
Gerek ikilik (binary) gerekse yazı (text) türü verilerle işlem yapmak için çok sayıda işlev bulunmaktadır. Dahası, dosyaları bir veri yapısı gibi doğrudan kullanmak olanaklıdır. Bunlara ek olarak sırtlı düzeni (file system) ilgili olanlar, ZIP gibi belgelik (archive) dosyalarının oluşturulması ve sökülmesi ilgili olanlar sırtlı (file) ve akım (stream) alanındaki Python desteği olarak sayılabilir.
İşletim Düzeni (Operating System)
İşletim düzenine erişim için çok sayıda işlev bulunmaktadır. Örnek olarak kütükleme (logging); süreçler (processes) ve yivler (threads) gibi konular sayılabilir. Pyhton dilinde güvenlik (security) ve şifreleme (cryptography) konularında da destek bulunmaktadır. Özellikle UNIX ve Linux için gelişmiş araçlar sunmaktadır. Veri bilimi için kullanımı yaygınlaşmadan önce Python dili işletim düzeninde kolay işlem yapmak için kullanılan bir betim (script) dili olarak kullanılmaktaydı. Bu nedenle bu konuda araçları son derece gelişmiş durumdadır. Bu nedenle düzen desteği (systems support) ve veri güvenliği (data security) ile ilgili olan kişiler Python ile çalışmayı yeğleyebilmektedirler. Bunun dışında Python çökertici (hacker) ve kırıcı (cracker) türü insanların da en yeğlediği araçların arasındadır.
Ağ (Network)
Pyhton ile TCP/IP ağları için priz (socket) programlama yapılabilir. Bu da Genelağ (Internet) üzerinden veri alışverişi için bir temel oluşturur. Bunun dışında bir çok iletişim kuralı (protocol) için destek bulunmaktadır. E-posta için POP3, SMTP, IMAP dışında FTP, HTTP, CGI gibi konularda da destek bulunmaktadır. Bu tür araçlar verilerin uzaktan alınması için kullanıldığı için veri bilimi için son derece yararlı olabilmektedirler.
Veri Biçimlenimleri (Data Formats)
Python dili veri biliminde yaygın olarak kullanıldığ için CSV, XML ve JSON gibi veri biçimlenimleri (data formats) desteği bulunmaktadır. Veri bilimini besleyen verilerin çoğu bir takım uygulamalardan ve veritabanlarından dışaverim (export) ile söz konusu biçimlenimlerde alınırlar. Bunların uygulamaya içealım (import) ile beslenmesi için bu biçimlenimlerin okunması gerekir. Düz veri dışında, HTML belgelerinin işlenmesi, XML kullanılarak SOAP protokolü, REST tekniği için destekler bulunmaktadır.
Görsel Arayüz (User Interface) ve Çokluortam (Multimedia)
Pyhton dili görsel açıdan çok varlıklı bir dil değildir. Dolayısıyla ön uç (front-end) yerine daha çok back-end (arka uç) alanında kullanılır. Ancak arayüz geliştirmek için Tk gibi araçlar bulunmaktadır. Tk dışında çoğu C/C++ tabanlı olan Qt, GTK ve wxWidgets gibi betiklikler de arayüz geliştirme için kullanılabilir. Kullanıcı görsel arayüzü dışında işitim (audio) ve görüntü (video) gibi çokluortam (multimedia) araçları için bir takım destekleri bulunmaktadır.
Sayısal (Numerical)
NumPy
Sayısal işlemleri yapmak için NumPy adlı bir betiklik bulunmaktadır. Yalnızca sayılar için değil gelişmiş matematik işlemler için de destek bulunmaktadır. Bu biçimiyle,bir çok bilim dalı ya da iş alanında kullanılabilecek, hemen her temel işlevi barındırmaktadır. Genel olarak, çok buyutlu dizi (multi-dimensional array) biçimde, çok sayıda veri içeren konularda ile çalışmak için araçlar içerir. Başka bir deyişle, büyük boylu sayılarla çalışmak için kullanılır.
SciPy
Temel işlevlerin ötesinde bir çok bilim dalında hazır bir çok özellik içeren betikliklerden birisi de SciPy adını taşır. Bu betiklik; çizgizel cebir (linear algebra), türetme (derivation) ve bütünleme (integration), sayımbilim (statistics), eniyileme (optimization) konularında bir çok araç içermektedir. Bunun dışında içucaylama (interpolation) ve dışucaylama(extrapolation), imgecilik (imaging), belgi süreçleme (sign processing), hızlı Fourier dönüşümü (fast Fourier analysis) gibi bir çok bilim dalında geçerli araçları içermektedir. SciPy betikliği NumPy betikliği üzerine kurulmuştur. Dolayısıyla SciPy kurmak aynı zamanda NumPy kurulması anlamına da gelir.
Pandas
Python dilinde veri (data) ile çalışma için gerekli veri yapıları (data structures) içeren betiklik Pandas olarak adlandırılmıştır. Tek boyutlu veriler
derney (series) ve iki boyulu veriler
veri çatısı (data frame) olarak adlandırlır. Dosya ya da veritabanı kaynaklarından gelen veriler üzerinde çalışmak için çok sayıda araç içerir. Verinin yanlışlıklarının düzeltilmesi ve yitik verilerin doldurulması ile ilgi çeşitli araçlar içerir. Pandas betikliğindeki veriler işlenmeye ve görselleştirmeye hazır durumdadır.
Bozuntulama (Scraping)
Requests
HTTP iletişim kuralı ile örün (web) içeriğini indirmek için kullanılan betikliklerden (kütüphanelerden) birisi Requests adını alır. Python dilinin kendisinde olan HTTP desteğinin daha geniş bir sürümünü sunar. Ancak veri üzerinde çalışmak için gerekli bir takım araçları da sağlayarak geliştiriciyi iş yükünden kurtarır. Bu biçimiyle örün emekleyici (web crawler) gibi işlemler için uygundur
Görselleştirme (Visualisation)
Mathplotlib
Verilerin görselleşirme (visualisation) işlemi için Mathplotlib adı verilen betiklik kullanılılır. Söz konusu betiklikle çizge (graph) üretme için temel araçlar içerir. Amacı çizim işlemleri için sağlam bir alt yapı sağlamaktır. Bu araç, yalnızca çizim için değil çizilenleri bir imge (image) için saklayıp sunma için de destek sağlar.
Seaborn
Temel çizgeleme (graphics) ötesinde başta sayımbilim (statistics) gibi alanlarda çizimler yapmak için kullanılan betikliklerden birisi de Seaborn adını taşır. Bu betiklik Mathplotlib üzerine kurulmuştur. Ancak türlü veri yapılarından çizim yapılması işlemin kendiliğinden gerçekleştirir. Başka bir deyişle yalnızca veriler ve başlıklar verilirek çizge oluşturulabilir. Bu araçla çizgeleme (graphics), çizenek (diagram), çizit (chart) gibi çizime dayalı bir çok görsel sonuç üretilebilir.
Düzenek Öğrenmesi (Machine Learning)
Skitlearn
Python dili ile düzenek öğrenmesi (machine learning) yapabilmek için Skitlearn adı verilen betiklik kullanılabilir. Bu konuda
sınıflandırma (classsification),
gerileme (regression),
salkımlama (clustering) gibi düzenek öğrenmesine ilişkin bir çok alanda çok sayıda yöntem ve algoritma içermektedir. Bunların arasında
Yapay Sinir Ağı(Artificial Neural Network),
K-En Yakın Komşu(K-Nearest Neighbour),
Toy Bayes Sınıflayıcısı(Naive Bayesian Classifier),
Karar Ağacı (Decision Tree),
Rastgele Orman(Random Forest),
K-Bayağılar Salkımlama(K-Means Clustering),
Genetik Algoritmalar (Genetic Algorithms) gibi konular sayılabilir. Bu betiklik SciPy ve NumPy üzerine kurulmuştur.
TensorFlow
Google kurumunun veri akışı (data flow) gibi veri işlemekle ilgili betikliğinin adı TensorFlow adını taşır. Bu betiklikte düzenek öğrenmesi (machine learning) ile ilgili bir çok algoritma desteği olduğu için bu alanda da kullanılır. Bilimsel işlemlerin ötesinde büyük veri (big data) ve dağıtık bilgisayım (distrubuted computing) alanında gerçek dünyaya ilişkin yüksek başarımlı çalışma olanağı sağlar.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning
Düzenek öğrenmesinde sınıflandırma (classification), salkımlama (clustering), gerileme (regression), yoğunluk kestirimi (density estimation), boyutsallık indirgemesi (dimensionaltiy reduction) gibi konularda; gerek gözetimli (supervised) gerekse gözetimsiz (unsupervised) yollarda uygulanan bir çok yöntem (method) ve algoritma (algorithm) bulunmaktadırBunlardan bir kesimi belli bir düzenek öğrenmesi(makine öğrenmesi) için kullanılırken bir kesimi birden çok yerde kullanılabilir. Bunların sayısı yüzlerce, küçük değişiklikler yapılmış sürümleri de sayılırsa binlerce olabilir. Burada çok bilinenlerinin ne olduğu kısaca açıklanacaktır. Buradaki açıklamalardan algoritmaları tümüyle anlamak olanaklı değildir, yalnızca ne oldukları konusunda genel bir bilgi verilmektedir.
Yapay Sinir Ağı (Artificial Neural Network)
Gözetimli öğrenme yöntemlerinden birisinin adı da yapay sinir ağı (artificial neural network) adını taşır. Bu adı verilmesinin nedeni canlılardaki sinir ağlarına benzetilmesidir ki bu benzerlik de çoğu kişi için tartışmalıdır. Bu algoritmayla hem sınıflandırma (classification) hem de salkımlama (clusering) yapılabilir. Bu yöntemde veri kümesi bir girdi (input) olarak kabul edilir ve her veri noktasının hangi sınıfa girdiği de bir çıktı (output) olarak algılanır. Girdideki her noktanın çıktıdaki noktaya olan etkisine ağırlık (weight) adı verilir. Örneğin insanların el yazısıyla girdiği sayıları anlamaya yarayan bir öğrenme düzeni tasarlayalım. Öncelikle daha önce el yazısıyla yazılımış 10 adet sayamak (digit) imgesi düzene girilir. Sonra bu imgelerdeki her benek (pixel) rakamın hangisi olduğunda bir ölçüde etkilidir. Öncelikle her beneğin her sayamak için etkisi bir ağırlık olarak alınır ve rasgele verilir. Sonra ne ölçüde doğru olduğuna bakılır. Şu andaki verilen ağırlık gerçek etkiden fazla sonuç çıkmasını sağlıyorsa azaltılır, eksik sonuç çıkmasını sağlıyorsa artırılır. Başka bir deyişle önce girdiğin çıktıya etkisi uydurulur ve sonuçların yanlışlığına bakılarak doğru yönde değiştirilir. Bu işlem girdinin çıktıya etkisini doğruya yakın olana dek sürdürülür. Ara aşamalar henüz doğru sonucu vermediği için saklı (hidden) tutulur. Arada kaç saklı aşama olacağı doğruluğa ulaşmak için ölçütün ne olduğuna doğrudan bağlıdır. Rakam türü girdilerde 4 ve 7 değerlerini örnek olarak alalım. 4 sayamağı için sol alt, sol üst köşelerdeki beneklerin boş, sağ üst ve sağ alt köşelerdeki beneklerin dolu olması gerekir. 7 sayamağı için de sağ alt ve sol alt köşedeki benekler boş, sağ üst ve sol üst köşedeki benekler doludur. Dolayısıyla, sol üst köşedeki benekler için 4 ve 7 rakamının değerleri başlangıçta ne olursa olsun, sonuçta sol üst köşedeki beneklerin 4 için sıfıra yaklaşırken 7 için 1'e yaklaşır. Başka bir deyişle, yapay sinir ağları, verilerin hangi kesiminin sonuçtaki sınıflandırmada ne ölçüde etkili olduğunu deneyerek ve yanlışlarından öğrenerek bulur. Her denemeden sonra yanlış olan değeri daha doğru değerle değiştirirerek doğruya ulaşır.
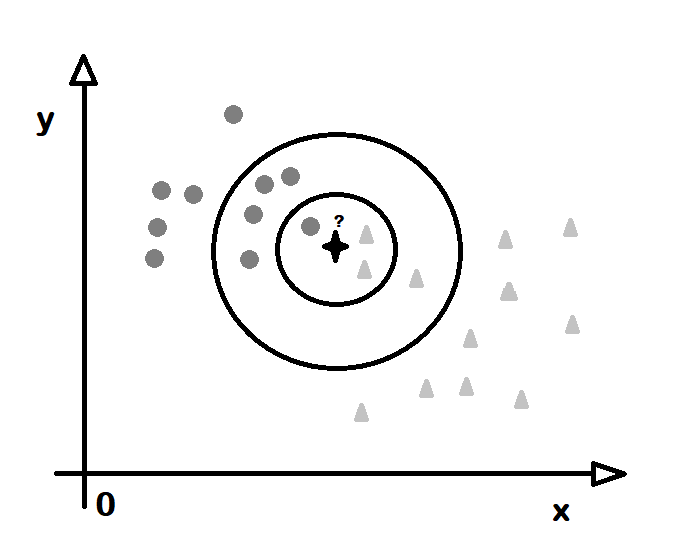
K-En Yakın Komşu (K-Nearest Neighbour)
Düzenek öğrenmesinde gözetimli öğrenme türüne giren sınıflandırma (classification) algoritmalarından birisi de k-en yakın komşu (k-nearest neighbour) adını alır. Temel mantığı, bir noktanın hangi sınıfta olduğunu, kendisine yakın belli sayıda noktaların hangi sınıfa ait olduklarına bakılarak bulunmasıdır. Buna göre bir noktanın 10 komşusundan 2 adedi A sınıfına, 7 adedi B sınıfına 1 adedi de C sınıfına aitse bu durumunda o noktanın B sınıfına ait olduğu sonucuna varılır. Burada komşu (neighbour) bir noktaya en yakın, uzaklığı en az olan noktalar anlamına gekir. Burada uzaklık (distance) hesaplama yöntemi dışarıdan bildirilir. Örneğin iki boyutlı veride iki nokta P1 (x1,y1) ve P2 (x2,y2) olsun. Aralarındaki uzaklık x değerleri arasındaki uzaklğını saltık (absolute) değerleri ile y değerleri arasındaki uzaklığın saltık değerlerinin toplamı olabilir. Ya da üçgenden yola çıkılarak uzaklık koordinatlar arasındaki farkların karalerinin toplamının karekökü olabilir. Bir noktanın bir noktaya olan uzaklık değerinin hesaplama yöntemi belirlendikten sonra bakılacak komşuların sayısı bilinmelidir. Buradaki k sayısı, k sayıda komuşunun hangi sınıfa girdiğine bakılacağını bildirir. O yüzden k sayısının seçilmesi kimi durumlarda sonucu değiştirir. Örneğin 5 komşudan 3 tanesi X sınıfına giriyor diye noktanın X olduğu düşünülebilir ancak k değeri 10 alınırsa ve 3 tane X, 5 tane Y bulunursa bu durumda noktanın Y olduğu düşünülür. Komşu sayısı 20 olursa ve 3 tane X, 5 tane Y varkan 9 tane Z komşusu varsa bu durumda da nokta Z kümesine girer. O yüzden sonucu pek fazla değiştirmeyen bir K değeri seçilir.
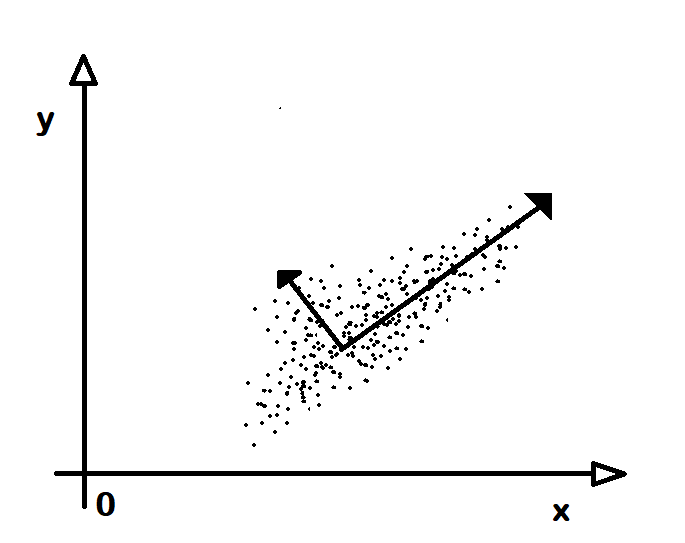
İlkesel Bileşen Çözümleme (Principal Component Analysis)
Birden çok boyuttan oluşan verilerden veriler arasında belli bir ilinti (corelation) olabilir. Örneğin insanların boyları ve kiloları birer boyut olsun. İnsanların boyları arttıkça kiloları da artacağı açıktır. Bu durumda bir insanın cinsiyetine ya da yaşına karar verirken doğrudan kilo ve boy değerlerini kullanmak doğru olmayabilir. Çünkü ikisi arasında çoktan bir ilişki var. Genç yaştaki bir erkek ile olgun yaştaki bir kadının kilosu aynı olabilir. Bu gibi durumlarda kökendeki boyut değerlerine bir dönüşüm uygulanarak yeni boyutlar elde edilir. Artık bu yeni boyutlar birbiriyle ilintili değildir ve karar vermekte kullanılmaya daha uygun olur. Ancak bu dönüşümün yapılabilmesi için yeni boyutların eksen (axis) konumları bulunmalıdır. İşte, dönüşümün taban alınacağı eksenleri bulma işlemine ilkesel bileşen çözümleme (primary component analysis) denir. Her bir eksene de bileşen (component) adı verilir. Bu yöntemde yeni eksenlerden hangisinin daha önemli olduğu, daha doğru bir deyişle, hangisinde verilerin değişkenlik sunduğu bulunur. En çok değişkenlik bulunan bileşen en önemlisi, ötekilerde buna göre sıralarak elde edilir. Buna göre öncelikle en çok değişlenlik gösteren dönüştürülmüş boyuta göre öncelikli kararlar verilir.
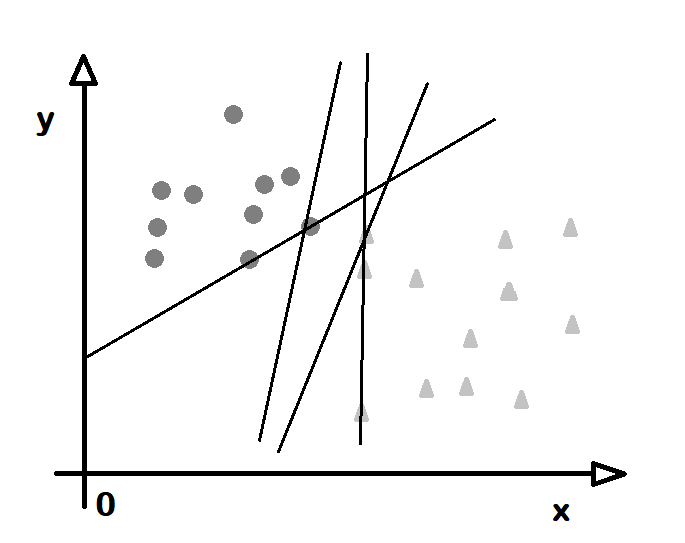
Destek Yöney Düzenekleri (Suppor Vector Machines)
Düzenek öğrenmesinde sınıflandırma (classification) ve gerileme (regression) işlemi için destek yöneyi (support vector) adı verilen yapılar kullanır. Bunlar, bir çok boyuttan oluşan uzayı bölen çizgi ve düzlemlerdir. Kaç boyut varsa bir eksiği boyutta tanımlanırlar. Örneğin iki boyutlu bir veride bir çizgi çizilir ve belli bir sınıf bu çizginin bir yakasında kalırsa bu bir destek yöneyidir. Her sınıf için bir destek yöneyi bulunur ve yeni bir değer verildiğinde bu değerin hangi sınıfta olduğu bu yöneye göre belirlenir. Boyut sayısı 3 olunca destek yöneyi bir düzlem olur. N boyutlu bir düzende, uzayı bölen yöneye aşırıdüzlem (hyperplane) adı verilir. Dolayısıyla destek yöneyleri uzayı bölen aşırıdüzlemlerden oluştur. Kimi durumlarda bir sınıfa ait noktalar bir arada olsalar da başka sınıfların içinde ya da çevresinde olabilir. Bu durumda araya bir düzlem koymak olanaksız gibi görünebilir. Bu durumda evin (kernel) adı verilen işlevler kullanılır. Noktalara öyle bir dönüşüm uygulanır ki artık hepsi bir düzlemin bir yakasında kalır.
Toy Bayes'çi Sınıflayıcı (Naive Bayesian Classifier)
Bir veri kümesinde hangi noktanın hangi sınıfa girdiğini olasılık (probabilty) kuramlarından Bayes kuramına göre bulan algoritmaya toy bayes'çi sınıflayıcı (naive bayesian classifier) adı verilir. Bayes kuramı, daha önceden bir kaç olay arasında ilişki görünmesi durumunda, sonraki olaylarında aynı değerlere bakarak var olan ilişkilerinin bulunmasıdır. Örneğin gönderilen bir e-postanın değersiz (spam) olup olmadığını anlamak için insanların daha önce değersiz olarak işaretlediği e-postalardaki sözcüklere bakılır. Örneğin "ikramiye kazandınız" gibi bir tümce hep değersiz e-postalarda çıkıyor da gerçek kişilerin gönderdiklerinde hiç çıkmıyorsa içerisinde sözkonusu sözcüklere geçen e-postaların değersiz olma olasılığının yüksek olduğu söylenebilir. Buna göre bir yazının içindeki sözcüklerin sıklık (frequency) bilgileri bulunur ve değersiz e-postalarınkiyle karşılaştırılır ve değersiz olma olasılığı bulunur. Bu yönteme toy (naive) denmesinin nedeni, gerçekte ilişkisiz de olsa yakın konumlarda bulunan verileri ilişkili sanabilmesidir. Örneğin beslenen verilerdeki değerlere eşit ele alış göstermekte boyutlardan hangisinin daha önemli olduğuna bakmamasıdır. Burada anlatılan dışında olasılık sınıflayıcı (probabilty classifier) türleri de vardır ve bunlar daha gelişmiş olasılık modellerine göre sınıflandırma yaparlar.
\( P (C|A)=\frac{P(A|C)P(C)}{P( A )} \)K-Bayağılar Salkımlama (K-Means Clustering)
Bu yöntem salkımlamada bayağı (mean) adı verilen, aritmetik ortalama (average) gibi değerlere bakılarak bir noktanon hangi sınıfa girdiğine karar verilir. Buradaki k harfki k adet sınıf olacağının baştan verileceği anlamına gelir. O yüzden bu algoritmaya k-bayağılar salkımlama (k-means clustering) adı verilir. Bu yöntemde bir bayağı değere yakın olanlar o bayağı değerin özeğinde bulunduğu sınıfın bir parçası sayılırlar. Başka bir deyişle, bir nokta kime yakınsa onunla birlikte olur. Bu yöntemde bayağı değerlerin sayısı baştan bellidir ancak kendileri baştan belli değildir. O yüzden öncelikle rasgele bayağı değerler bulunur. Sonra her noktanın bu bayağı değerlere olan uzaklığı alınır ve yakın olan noktalar o sınıfa konur. Sonra noktaların eklendiği sınıfların yeni bayağı (mean) değerleri, örneğin aritmetik ortalaması alınır. Sonra bu yeni bayağılara göre her noktanın uzaklığı hesaplanırve her nokta kendisine en yakın olan bayağının sınıfına sokulur. Bu süreç, tüm noktalar aynı yerde kalana dek, yani yer değişmeler bitene dek sürer. Başlangıçta bir nokta belli bir bayağının sınıfına girer ancak bir süre sonra yeni bayağı ondan uzaklaşabilir ve o da başka bir sınıfa girer. Son durumda hem bayağılar sınıflarındaki noktalara en az uzaklıkta bulunmuş olurlar hem de her nokta kendisine en yakın bayağının sınıfına girmiş olur. Burada anlatılan yöntemin ortanca (median) değerine bakarak karar verildiği k-ortancalar salkımlama (k-medians clustering) adı verilen bir değişiği de bulunmaktadır.
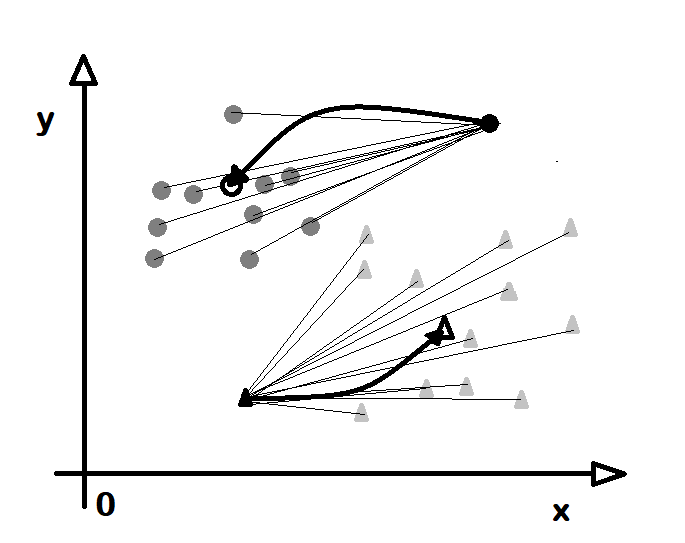
Genetik Algoritmalar (Genetic Algorithms)
Biyolojideki evrim kuram (evolution theory) dirilerin türlülüğünü açıklamaya yaramaktadır. Buna göre dirilerin kimi bireylerinde genlerinde rastgele bir değişinim (mutation) olur. Daha sonra bu değişinime uğrayan bireylerden çevreye uygun olanlar doğal seçilim (natural selection) ile çoğalırken uygun olmayanlar giderek yok olur. Uzun süre geçtikten sonra bu değişinimler sonucunda her yinelenme (iteration) daha iyiye doğru gider. İşte genetik algoritmalar (genetic algorithms) de bu yöntemle sonuçlar üretir. Genellikle eniyileme (opimization) ve arama (search) konularında işlev görürler. Buna göre önce derneşim (permutation) ile rasgele bir öbek sonuç üretilir. Sonra her sonucun ne denli doğruya yaklaştığına bakılır. Sonra doğruya en uzak olanlar atılır ve yeni değerler daha doğru olanlardan oluşan katışım (combination) olarak yeniden üretilir. Buna karşıya geçme (cross over) adı verilir. Yine oluşan durumlardan her birinin doğruluğu sınanır ve yine doğruya uzakların atıldığı yakınlardan katıştırılarak sonuçların üretildiği işlemler yinelenmeli olarak, en doğru sonuç bulunana dek sürdürülür. Bu algoritma olabilecek eniyi (optimum) sonucu her durumda vermez ancak ilişkin olarak daha uygunları bulabilir.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning
Python dili için bir çok geliştirme ortamı (development environment) desteği bulunmaktadır. Bunlardan bir kesimi düzgü eğirici (code editor) adı verilen, temel geliştirme işlemlerini içerip çok ileri düzeyde görsel araçlar içermeyen uygulamalardırPython dili için bir çok geliştirme ortamı (development environment) desteği bulunmaktadır. Bunlardan bir kesimi düzgü eğirici (code editor) adı verilen, temel geliştirme işlemlerini içerip çok ileri düzeyde görsel araçlar içermeyen uyalamalardır. Bunlar temelde bir yazı eğirici (text editor) uygulamasını düzgü renklendirme (code colorizing) ve düzgü tümleme (code completing) gibi özellikler eklenmesiyle oluşur. Öte yandan Bütünleşik Geliştirme Çevresi (Integrated Development Environment) adı verilen, bir çok gelişmiş araç içeren uygulamalar da bulunmaktadır. Bunların bir kesiminde düzgü yazmak yerine bir takım pencerelerde tıklama yaparak geliştirme yapmak olanaklıdır.

Kimi geliştiriciler düzgü eğirici (code editor) kullanmayı yeğlerler. Çünkü temel destek onlar için yeterlidir ve karmaşık bir arayüze gerek duymazlar. Ancak düzgü eğiriciler kimi kişilerce çok yetersiz olarak algılanmaktadır. Özellikle başka bir dil için gelişmiş araçlar kullananlar için düzgü eğirici çok yetersiz kalabilmektedir. Öte yandan kimi geliştiriciler için de bütünleşik geliştirme çevresi (integrated development environment) uygulamaları gereksiz karmaşık gelebilmektedir. Geliştiriciler çok sayıda özellik arasında yitebilekte, geliştirme yapmak yerine kedilerini çevrenin bileşenlerini öğrenmekte bulabilmektedir.
Temel Araçlar
IDLE
Pyhton programlama dilinin doğal geliştirme çevresi IDLE adını taşır. Python dilini öğrenmek isteyenler için gerekli temel araçları sağlar. Ancak temel özellikler ötesinde gelişmiş özellikler içermez. İstenirse bir takım betiklikler yüklenerek gelişmiş uygulamalar geliştirilebilir ancak bu çevre, geliştirme için pek çok kolaylık içermez. IDLE çevresi, Pyhton ile çizgelemeli kullanıcı arayüzü (graphical user interface) geliştirme betikliği olan Tkinter iler geliştirilmiştir. Tkinter, işletim düzeni (operation system) çevresinden bağımsız olarak görsel arayüz geliştirilmesine olanak veren bir zımbırtı (widget) betikliğidir.
Yazı Eğiriciler (Text Editor)
Pyhton ile geliştirme yapmak için Notepad++ gibi herhangi bir yazı eğirici (text editor) kullanılabilir. Bunlar Pyhon dilin tanır ve kodları renkli gösterir. Olağan yazı eğirme özelliklerini de sağladıkları için bir çok kişi, başka diller için alıştığı bu uygulamaları Python için de kullanır. Özellikle aynı anda bir çok programlama diliyle çalışanlar bu tür genel araçları yeğlemektedirler.
IPython

Python dilinde etkileşimli (interactive) bir geliştirme yapılmasına olanak veren IPython adında bir çevre bulunmaktadır. Bu araçlar geliştirme yapmakla bir takım matematik uygulamlarının konsolunda çalışmak aynı anda yapılmaktadır. Bir parça kod yazıp çalıştırarak anında sonuç görülebilmesi sağlanmaktadır. Öte yandan buyruk çizgisi (command line) araçlarıyla çalışmayanlar için çok düşük düzeyli, kullanımı çok çetin bir araç olarak görülebilir. Doğrudan bu çevreyi kullanmak yerine, bu çevreyi içeren daha gelişmiş bir uygulama yeğlenebilir.
Pip
Python dilinin bohça yöneticisi (package manager) uygulamsına Pip adı verilir. Bir betiklik (library) indirmek için kullanılır. İndirilen betikliğin kullandığı betiklikleri de özyinelemeli (recursive) olarak indirir. Tek başına bir araç olmaktan çok başka çevrelerin altında kullanılan bir özellik olarak işlev görür. Python dilinin geliştiricilere sağladığı betikliklerin çok geniş olduğu düşünülürse, bohça yöneticinin ne denli önemli olduğu anlaşılabilir.
Gelişmiş Araçlar
Jupyter Betlek (Jupyter Betlek)

IPython çevresinin geliştirilerek betlek arayüzü (notebook interface) adı verilen yönteme uygun bir çevre sağlayan Jupyter Betlek (Jupyter Betlek) adlı bir araç geliştirilmiştir. Betlek ya da defter adı verilen uygulamalar, kağıttan oluşan defterle çalışır gibi gelişirme ya da kullanım yapmak anlamına gelir. Bir anlamda geliştirme çevresi (development environment) ile sözcük süreçleyici (word processor) arası, ikisininde özelliklerini taşıyan araçlardır. Bir çok dil ve uygulama kullanıcıların daha rahat kullanımı için bu tür araçlar sağlamaktadır. Jupyter de betlek arayüsü kavramının Python dilindeki karşılıklarıdır. Öte yandan, Pyhton dışında R ve Julia adlı veri bilimi dillerini de desteklemektedir. Uygulama geliştirmekten çok deneme yanılma yoluyla bir takım işlemleri öğrenmek için son derece uygundur. Öte yandan yapılan işlemlere ilişkin düzgü (code) parçaları saklanıp yeniden kullanılabildiği için de bir geliştirme çevresi olarak da işlev görebilir.
Spyder

Pyhton ile geliştirme yapmak için kullanılan araçlardan birisi de Spyder adını taşır. Özellikle veri bilimi (data science) ve düzenek öğrenmesi (machine learning) konularında bir çok gelişmiş araç içerir. Geliştirme çevresi çok görsel araç içermese de hazır bir çok betiklik içerdiğinden akademik ve bilim düyasında yaygın olarak kullanılır. Anaconda adı verilen bir dağıtım (distribution) içinde Pyhton ve R desteği içerir. Spyder; Numpy, Scipy, Mathplot betikliklerini ve IPython etkişleşimli bilgisayım çevresini içinde barındırır. Bunların dışında da açık kaynaklı bir çok betiklik, Spyder ile birlikte gelir.
PyCharm

Java dilinde ileri düzeyde geliştirme çevresi (development environment) sağlayan JetBrains kurumunun IntelliJ adlı Java çevresinin Pyhthon diliyle geliştirme yapmak için üretilmiş sürümüdür. Android ile geliştirme yapanların kullandığı Android Studio çevresi de IntelliJ tabanlıdır. Çoktan Java için yapılmış özelliklerin Python ortamına aktarır. Özellikle Java ve Android gelişiyirme yapanlar için tanıdıdık bir çevre sağlar. Kurmadan önce Java motorunun kurulması gerekir.
PyDev

Yine Java ile yazılmış, en yaygın kullanılan geliştirme çevrelerinden birisi olan Eclipse tabanlı bir Python çevresi olarak PyDev sayılabilir. Eclipse çevresine tanışık olan ya da dolaylı olarak da Eclipse tabanlı başka bir eğiriciyi kullananlara bu uygulama önerilir. Bu çevre için de Java motorunun kurulması gerekir.
Visual Studio için Pyhton Araçları
Microsoft kuruluşunun C# gibi dillerler .NET üzerinde geliştirme yapmak için kullanılan çevresi Visual Studio uygulamasında Visual Studio için Pyhton Araçları (Python Tools for Visual Studio) adı verilen bir eklenti kurarak Python geliştirme yapılabilir. Visual Studio hem gelişmiş hem de kullanımı kolay bir çevre sağlamaktadır. Ancak daha önce kurmamış olanlar için kurulması çok uzun sürebilmektedir. Çünkü Visual Studio, Microsoft kurumunun Windows işletim düzeni için gerekli tüm araçları kurmaktadır. Dahası, gerektiğinde işletim düzenini ya da temel uygulamaları güncelleme gibi bir durum da söz konusu olabilmektedir.
Öneri
Python ile geliştirme yapmaya başlayanları Pyhon dilinin doğal ortamı IDLE ile başlamaları önerilebilir. Öte yandan, gerçek amacı Python öğrenmenin yanında veri bilimi (data science) ve yapay us (artificial intelligence) öğrenme amacında olanlar Spyder önerilebilir. Öte yandan, verilerler çalışarak hemen sonuçları görme biçiminde çalışmak isteyenler için Jupyter çok uygun bir çözüm olarak görülmektedir. Ancak daha önce Java Girişim (Java Enterprise) için uygulama geliştirenlere ya da zamanla geliştirmek isteyenlere Eclipse tabanlı PyDev; Android Studio ile taşınabilir aygıtlar yapanlara veya yapmayı düşünenlere IntelliJ tabanlı PyCharm önerilir. C#.NET gibi Microsoft teknolojilerine tanışık olan ya da uzun dönemde bu yönde ilerlemek isteyenlere de Visual Studio için Pyhton Araçları (Python Tools for Visual Studio) önerilir. Başlangıçta Spyder gibi bir ortamla giriş yapıp sonrasında sayılan seçeneklerden birisine geçmek de izlenebilecek yollardan birisidir.
Python kursunda programlamanın temel konuları dışında veri bilimi (data science) ve yapay us (yapay zeka - artificial intelligence) konuları için gerekli temel konular anlatılır. Ancak bu kurs belirtilen konular dışında da Python programlama ile ilgili alanları da kapsar.Python kursunda programlamanın temel konuları dışında veri bilimi (data science) ve yapay us (yapay zeka - artificial intelligence) konuları için gerekli temel konular anlatılır. Ancak bu kurs belirtilen konular dışında da Python programlama ile ilgili alanları da kapsar. Başka bir deyişle, Python dili ile geliştirme yapmak isteyen kişilerin bilmesi gereken hemen her şeyi içermektedir.
Python İle Programlama
Temel Konular
Python dili ile betim (script) yazmak için gereken söz dizimi (syntax) öğeleri bilinmelidir. Her dilde olan, ekrana basma (echo) ve ekrandan girdi okuma (read input) işlemleri öğrenilmelidir. Temel konular arasında değişken (variable) kavramı ve veri türleri (data types) iyi anlaşılmalıdır. Özellikle sicim (string) ve sayı (number) türleri en çok bilinmesi gereken veri türleri arasındadır. Python diliyle işlenen verilerin çoğu sicim ve sayı türündedir.
Her yazılım geliştirme dilinde olduğu gibi Python dilinde de akış denetimi (flow control) adı verilen yapılar kullanılır. Örneğin koşul (condition) yapıları için if-else (ise-değilse) ve açkı (switch) yapısı kullanılır. Dilde döngü (loop) yapılarından için (for) ve sürece (while) bilinmelidir. Bu yapılar, verileri satır satır alıp okumak ve işlemekte kullanılır.
Gelişmiş Yapılar
Python dilinde temel yazılım geliştirme özellikleri dışında gelişmiş yapılar da bulunur. Bunlardan işlev (function), sık sık yapılan işlerin bir kez yapılıp sürekli kullanılmasını sağlar. Bir çok işlevden oluşan ve modül (module) adı verilen, ayrı dosyalarda tutulan kod parçaları da yazılabilir. Yazılan kodda bir modülü kullanmak için içe alma (import) işlemi yapılır. Söz konusu araçlar temelin ötesinde gelişmiş uygulamalar yazmak gereklidir ancak bir çok kişi bu biçimde yazdığı için öğrenilmeleri çoğu durumda koşuldur.
Birden çok veriyi tutmak için dizi (array) adı verilen yapılar bulunur. Python dilinde dizilerin kullanımı oldukça kolaydır ve bir çok gelişmiş özellik içerir. Ancak kimi zaman sağladığı çok sayıda kolaylığı öğrenciler karıştırabilmektedirler. Dizi dışında daha gelişmiş veri tutma özelleri barındıran dizelge (list), sözcük (dictionary) ya da kimi dillerde bilinen adıyla eşlem (map), küme (set) gibi biriktiri (collection) yapıları da bulunmaktadır. Birbiriyle ilintili veriler, örneğin kayıtları tutmak için demet (tuple) adı verilen bir yapı bulunur. Bunlar verilerin toplu bir biçimde işlenmesi için gereklidir. Çoğu sorunu çözmek için yukarıdaki veri yapılarından biri veya bir kaçı birlikte kullanılır.
Nesne-Yönelimli İzlendirme (Object-Oriented Programming)
Python dili işlevsel izlendirme (functional programing) adı verilen, kod yazımını bir takım işlev (function) yapılarıyla gerçekleştirmek ve gerektiğinde bunları çağrımak biçiminde yapılan tekniği desteklediği gibi nesne-yönelimli izlendirme (object-oriented programming) adı verilen tekniği de destekler. Buna göre belli bir konuyla ilgili değişken (variable) ve işlev (function) birimleri bir arada sınıf (class) adı verilen karmaşık tür bildirimleri yapılır ve bunlardan nesne (object) ve örnek (instance) adlı karmaşık veri tutan yapılan üretilir.
Uygulama ve Örnekler
Eğitimlerde temel konularda uzun uzun örnekler yapılması yerine, daha ileri konularda bunları yerinde kullarak anlatılması yoluna gidilmektedir. Özellikle daha önce başka bir programlama dilinde çok temel yapıları genel olarak da olsa bilenler için giriş konularında takılmak yerine ileri konular çabuk geçiş sağlanması konuların iyi anlaşılmasını sağlayabilir. Örnekler bir tablonun ve onun satırlarının üzerinde çalışma, verileri sicimden sayıya ya da sayıdan sicime dönüştürme ve sicimler üzerinde kimi değişiklikler yapma biçiminde gerçekleştirilmektedir. Bu işlem de veri bilimi gibi veriler üzerinde işlem yapan konular için öğrenilmesi koşul olan konulardır. Başka bir deyişle, örnekler kuramsal değil gerçek yaşamdaki uygulamalara göre belirlenmektedir.
Veri Dosyaları, İşleme ve Görselleştirme
Dosyalar
Python dilinde sırtlı (dosya - file) işlemleri için bir çok destek bulunur. XML, JSON ve CSV gibi bir çok veri saklama biçimlenmesinde yazılmış dosya Python dilinde kolayca okunabilir veya bunlara yazma yapılabilir. Öte yandan örün (web) ve veritabanı (database) işlemleri için kullanılan sunucuya göre bir betiklik (library) yüklemek gerekebilir. Bu yolla HTML, SQL ve NoSQL gibi konularda destek sağlanmış olur. Python dilinde veriler çoğunlukla dosyalar biçiminde girdi olarak alınır ve sonuçlar da dosya biçiminde çıktı olarak verilir. Bunun en önemli nedeni işlenecek verilerin veritabanı gibi kaynaklardan gelmesi ve bu kaynaklara doğrudan bağlanmak yerine onlardan dışa alma (export) ile edinilmiş dosyalarda çalılmasıdır. Bu biçimde Python geliştiricisi veritabanlarıyla doğrudan uğraşmak durumunda kalmaz. Öte yandan, sonuçların dosya olarak üretilmesi de bunları işlenmek üzere OpenOffice veya Microsoft Office gibi uygulamaların kullanabilmesini sağlar. Bu nedenler bir çok veri işleme süreci dosyadan ana verileri alıp sonuçları dosyalara üretir.
Çizitler (Charts) ve Graphics (Çizgeleme)
Python dili için matplotlib gibi bir çok betiklik (library) çizim yapmaya olanak verir. Desteklenen işlemler histogram ve pasta gibi çizit (chart) yapıları ve analitik geometri gibi konular için çizgeleme (graphics) yapma gibi işlemler sayılabilir. Söz konusu betiklik Python dilindeki dizi (array) ve demet (tuple) benzeri yapıları doğrudan destekler. Örneğin bir demet dizisini parametre olarak verip, hangi sütunlarda hangi işlemler yapılacağı söylenirse ona göre bir çizit oluşturulabilir. Python gibi diller verilerin işlenmesi dışında görselleştirme (visualization) için de kullanıldığı için çizgeleme araçları önemli bir işlev görürler. Dahası, bir çok kişi Python dilini, başka araçlarında eklenmesiyle birlikte R veya MATLAB gibi bir matematik uygulaması gibi kullanır. Bu nedenler görselleştirme bilinmesi gereken önemli bir konu durumundadır.
Örnekler ve Uygulama
Eğitim boyunca gerçekte kullanılan veri türlerinden olşturulmuş dosya türleriyle çalışılmaktadır. Özellikle veri bilimi (data science) için veritabanlarından dışa alma (export) ile edinilmiş dosyaların okunması üzerinde durulur. Verilerin okunduktan sona sayımbilim (statistics) özetlerinin çıkarılması ve çizgeleme (graphics) ile kullanıcıya gösterilmesi biçiminde örnekler yapılmaktadır. Bu örnekler Python ile yapılan; matematik, bilim (fen), teknoloji ve iş dünyasında gerçekten kullanılan yöntemlere bir taban oluşturmaktadır. Buradaki örnekleri anlayarak yapabilenler için sonraki konuları anlamak daha kolay olacaktır.
Yararlı Betiklikler
İşletim Düzeni (Operating System)
Python dili ile işletim düzeni (operating system) ile ilgili bir çok işlev bulunmaktadır. Bunlar arasında kütükleme (logging), süreçler (processes), yivler (threads) gibi konular sayılabilir. Bunların dışında güvenlik (security) ilgili destek ileri düzeydedir. Python dili, ilk başlarda veri bilimi gibi bir alan için kullanılması için değil, işletim düzenlerinde bir çok işlemi kolay yapmak için yazılmıştır. Dolayısıyla düzen destek (system support), yığın görevleri (batch jobs) ya da güvenlik (security) gibi konularda işlem yapanlar için çok geniş destekler bulunmaktadır. Bu yönüyle işletim düzenin bir kabuk (shell) üzerinden kullanmaya göre son derece gelişmiş bir altyapı sağlar.
Ağ (Network)
Python dili TCP/IP düzeyinde hem TCP hem de UDP ile priz programlama (socket programming) gibi düşük düzeyli ağ (network) işlemlerini desteklemektedir. Bunun dışında POP3, SMTP, IMAP, FTP, HTTP gibi çok sayıda iletişim kuralı (protocol) desteklenmektedir. Söz konusunu konular tek başlarına çok yararlı gibi görünmese de gelişmiş bir uygulama bu konulardan birini ya da bir kaçını kesinlikle içerir. Öte yandan buradaki betiklik (library) seçenekleri doğrudan kullanılmak yerine, bunların üzerine geliştirilmiş daha ileri düzeyde betiklikler de yeğlenebilir. Ancak ileri modülleri kullanmak için de temelleri, doğrudan kullanılmasa bile bilmek gereklidir.
Çizelemeli Kullanıcı Arayüzü (Graphical User Interface - GUI)
Python dilinin kendisinde bir kullanıcı çizelemeli kullanıcı arayüzü (graphical user interface - GUI) bulunmaz. Ancak Qt ve Tkinter gibi, C/C++ tabanlı gelişmiş ve işletim düzeninden bağımsız betiklikleri destekler. Bir çok kişi için Python arka-uç (back-end) yakasında kullanılan bir dil olsa da ön-üç (front-end) için de desteği bulunmaktadır. Ancak bu destek çoğunlukla sıradan kullanıcıların kullandığı masaüstü uygulamaları yapmaktan çok, işi verilerle ya da işletim düzeniyle çalışmak olan kişilere görsel bir arayüz sağlayan uygulamalar yapmak için kullanılır.
Örnekler ve Uygulama
Eğitim kapsamında örnek olarak bir sohbet (chat) uygulaması yapılmaktadır. Örnekte çok yivli (multi-threaded) bir sunucu (server) ve birden çok istemci (client) arasında ileti alışverişinde bulunulmaktadır. Qt ya da Tkinter ile görsel bir arayüz yapılarak sunucu ve istemci sınanmaktadır. Buradaki örnek, anlatılan konuların daha iyi anlaşılmasını sağladığı gibi daha gelişmiş ve karmaşık uygulamaların nasıl geliştirilebileceği konusunda da bir taban oluşturması açsından işletim düzeni, ağ ya da görsel arayüz gibi konularla ilgilenmeyen kişilere de önerilmektedir.
DJango Çatısı
DJango Çatısına Giriş
Python dili çoğunlukla işletim düzeni (operation system) üzerinde işleri kolaylaştıracak bir betim (script) dili ya da veri bilimi (data science) veya yapay zeka (artificial intelligence) gibi uzbilim (mathematics) ve bilgisayım bilimi (computing science) gibi konuları içeren alanlarda yaygın olarak kullanılır. Ancak örün (web) ve veritabanı (database) gibi alanlarda; Java, C#.NET ve PHP gibi dillerdekine benzer biçimde de kullanılabilir. Bu amaçla geliştirilen çatı (framework) ürünlerinden en yaygın kullanılanlarından birisi de DJango adını taşır. Bu çatıda olağan örün ve veritabanı konuları dışında ORM ve MVC gibi gelişmiş teknikler de desteklenir.
Örnek bir Örün Veritabanı Uygulaması
Eğitim sırasında örnek olarak bir veritabanı (database) ile çalışan örün uygulaması (web application) yapılamaktadır. ORM ve MVC tekniği ile CRUD adı verilen, tablolarda temel işlemleri içeren bir uygulama yapılamaktadır. Buradaki örnekle Python ile içerik (content), e-ticaret (e-commerce) gibi sitelerin nasıl yapıldığı da öğrenilmiş olur. Bu biçimde Java, C#.NET ve PHP gibi konulara da girmek isteyenler için öğrenme kolaylığı sağlar.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning
Bu eğitim, veri bilimi (data science) konularını Python diliyle anlatmaktadırBu eğitim, veri bilimi (data science) ve yapay us (yapay zeka - artificial intelligence) konularını Python diliyle anlatmaktadır. Her ne denli dil olarak Python seçildiyse de anlatılanların çoğu öteki diller için de geçerlidir. Dahası, öteki dillerde veri bilimi ve yapay us konularında çalışmak isteyenler için de Python ile başlamak, bu dilin göreli olarak daha kolay olması nedeniyle iyi bir başlangıç noktası olabilir.
Numpy ve Matplotlib ile Sayısal İşlemler ve Görselleştirme
Gerek veri bilimi gerek yapay us, sayılarla çalışmayı gerekli kıldığı için Pyhton dilindeki Numpy kütüphanesi öğrenilmelidir. Bu betiklikte(kütüphanede) olağan uzbilim (matematik) konuları için gereken sayısal işlemler bulunmaktadır. Numpy, yalnızca sayı ilgili değil, sayı dışındaki temel türlerle ilgili işlemleri içermektedir. Verilerle çalışmanın temellerini içerir.
Yapılan işlemleri daha anlaşılır biçimde inceleyebilmek için de matplotlib adı verilen görselleştirme (visualization) kütüphanesi kullanılır. Bu biçimde öğrencinin üzerinde çalıştığı veriyi daha iyi anlaması ve ona hakim olması sağlanır. Bu kütüphane aynı zamanda sonuçlarını sunulması ve yazanak (report) oluşturmak için gereklidir. Veri bilimiyle üretilen sonuçların bir biçimde akademik ya da iş dünyasına sonuç olarak sunulması gerekir.
Eğitimde Requests adı verilen HTTP iletişim kuralı üzerinden örün (web) içeriğini edinmeye yarayan bir betiklikte (kütüphanede) anlatılmaktadır. Bununla örün(web) üzerindeki içerikleri indirip üzerinde işlemler yapılabilmesi sağlanmaktadır. Var olan, hazır olarak sağlanan verilerle çalışmak yerine gerçek ve diri veri toplamanın yolları anlatılmaktadır.
Eğitim boyunca, düzenek öğrenmesi (machine learning) ve sayımbilim (statisitics) gibi konularda işlenecek verilerin dosyalardan okunması, üzerinde işlem yapılması ve görselleştirilmesine ilişkin örnekler yapılmaktadır.
Scipy ve Pandas ile Bilimsel İşlemler ve Veri İşleme
Temel matematik konularının ötesinde bilimsel konularda bir çok işlev içeren Scipy betikliğinin (kütüphanesinin) de bilinmesi gerekir. Burada science (bilim) ile denmek istenen doğal bilimler (natural sciences) olarak anlaşılmalıdır. Çünkü science sözcüğü tek başına kullanıldığında 'fen' anlamına gelmektedir. Scipy kütüphanesi Numpy kütüphanesini kullanır. Özel işlemler, türev (derivative) ve bütünlev (integral), içucaylama (interpolation), hızlı Fourier dönüşümü (fast Fourier transform), uzaysal yapılar ve algoritmalar (spatial structures & algorithms), sayımbilim (statistics) gibi konuları içerir. Bunlar hemen her yerde kullanılan matematik içeren yöntemlerdir.
Bilimsel konuların daha iyi anlaşılması için lisans düzeyinde matematik konuları gerekmektedir. Yer yer yetersiz kalındığı yerlerde yüksek matematik konularında da girilmektedir.
Eğitimde veri kümeleri edinilerek üzerinde türlü bilimsel işlem uygulanmakta ve sonuçlar görsel olarak incelenmektedir. Bu bölümde herhangi bir algoritmaya girmeden, birden çok algoritmada kullanılan temel bilimsel işlevlere yönelik uygulamalar yapılmaktadır.
Örnek Proje
Eğitim tümüyle uygulamalı yapılmaktadır. Her bölümde bir proje geliştirme için gerekli konular uygulamalı olarak örnek üzerinde anlatılmaktadır. Ancak eğitimin sonunda de her katılımcıya, anlatılanları içerdiği gibi kursun ötesinde de konulara girebileceği örnek bir proje verilmekte ve bu konuda öğrenciye destek olunmaktadır.
Bu konularda ayrıntılı bilgi, kurs, özel ders, uzaktan eğitim, ödev ve proje destek, kitap ve video için tıklayın :
Python Business Intelligence, Data Science ve Machine Learning