Elimizde aşağıdaki gibi veri bulunsun :
A 10
B 3
C 9
A 9
A 10
C 3
D 2
C 29
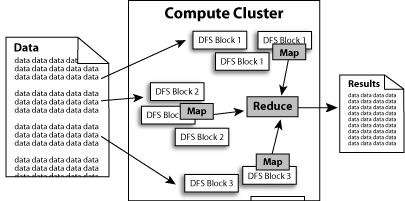
MapReduce ile A , B , C ve D için sayıların toplamı bulunabilir. Öncelikli olarak map ile tüm bilgi ne kadar iş birimi var ise o kadar bölüme parçalanır. 2 iş birimi olduğunu varsayılabilir :
1.Bölüm
A 10
B 3
C 9
A 9
2.Bölüm
A 10
C 3
D 2
C 29
Parçalama işleminden sonra bölüm her iş bölümünde ayrı bir şekilde reduce işleminden geçirilir ve toplam değerler hesaplanır :
1.Map
A 19
B 3
C 9
2.Map
A 10
C 32
D 2
Her iş biriminde tüm değerler reduce edildikten sonra toplam değerler içinde reduce işlemi yapılır ve sonuç elde edilir :
A 29
B 3
C 41
D 2
Aşağıda Hadoop ile bir dosyadaki kelime sayısını bulup başka bir dosyaya yazan örneğin kod görülmektedir :
package wordcount;import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class WordCount { public static class Map extends MapReduceBase implements Mapper<longwritable, text,="" intwritable=""> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<text, intwritable=""> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<text, intwritable,="" text,="" intwritable=""> { public void reduce(Text key, Iterator<intwritable> values, OutputCollector<text, intwritable=""> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
map fonksiyonu gelen içeriği key , değer şeklinde oluşturup output'a ekleme yapmaktadır. Bu şekilde tüm kelimeler key olarak ve değeri 1 olarak oluşacaktır. reduce'ta ise gelen değerler toplanmaktadır. Bu nedenle aynı kelime ne kadar gelir ise toplam değer bulunmuş olacaktır.