|
|
|
|
| htakci@bilmuh.gyte.edu.tr |
| ispinar@bilmuh.gyte.edu.tr |
Program davranışlarını saldırı ve normal kullanım şeklinde sınıflara ayırmada en yakın k komşu tabanlı bir sınıflayıcı kullanmak yeni bir yaklaşımdır. Program davranışları sistem çağrılarının istek sırası şeklinde verilebileceği gibi sistem çağrıları sıklıkları şeklinde de verilebilir. Y. Liao çalışmasında[1] her bir sistem çağrısının bir kelime ile, bir proses içerisindeki bütün sistem çağrılarının da bir doküman ile sunulabileceğini belirtmektedir. Bu çalışmada ise her bir web sayfası bir kelime ile her bir oturumda istenen sayfalar da bir doküman ile sunulmaya çalışılmıştır. Böylece doküman haline getirilen bu veriler metin sınıflamada kullanılan en yakın k komşu (kNN) sınıflayıcısı ile sınıflara ayrılabilir. Bu makalede saldırı tespiti için web sitesi kullanım davranışlarının öğrenilmesinde en yakın k komşu algoritmasının kullanımı anlatılmaktadır.
Güvenlik problemleri çeşitli nedenlerden dolayı her zaman olacaktır. Saldırı tespit sistemleri bu güvenlik problemlerini bulmada ve gidermede anahtar vazife taşımaktadır. Güvenlik kameralarına benzetilebilecek saldırı tespit sistemleri için ideal durum; yüzde yüz atak tespiti ve yüzde sıfır hatadır. Halbuki günümüzün saldırı tespit sistemleri bundan uzaktır.
Saldırı tespiti için iki temel yaklaşım bulunur. Bunlar; yanlış kullanım tespiti ile anormallik tespitidir. Yanlış kullanım tespiti imza tabanlıdır. Bu imzalar daha önceden yapılmış saldırı davranışlarını tanımlarlar. Özellikle ticari saldırı tespit sistemlerinde kullanılan bu tekniğin en önemli eksiği daha önce meydana gelmemiş saldırıları tanıyamamasıdır. Diğer yaklaşım ise anormallik tespiti yaklaşımıdır. Bu yaklaşıma göre önce normal kullanım profilleri bulunur ardından da bu profilden sapma gösterenler anormal olarak belirlenirler. Profiller bulunurken istatistiksel yöntemler kullanılmaktadır. Bu yöntemin ise en önemli problemi yüksek hata oranına sahip olmasıdır. Daha etkin saldırı tespiti için iki tekniğin birleştirilmesi yoluna gidilmektedir.
Son zamanlarda özellikle saldırı tespitinde davranış tanıma bir alternatif haline gelmiştir [2,3]. Bir programın profili program çalıştırılırken gözlemlenen ve programın çalışması esnasında oluşturulan sistem çağrılarının birleştirilmesinden oluşur. Kullanıcı davranışlarını karşılaştırmak için onların kullandığı programlardaki davranışlarını karşılaştırmak daha kalıcı bir çözümdür. Bir programın normal davranışı sistem çağrılarının sırası şeklinde karakterize edilebilir. Sapmalar ise program çalışırken gösterdiği değişimler olarak bulunur. Fakat bu yaklaşım sıkıcı bir yaklaşımdır [1]
Bu çalışma [1] numaralı makalede yapılan çalışmanın başka bir alana uygulanması çalışmasıdır. O makalede program davranışları saldırı tespiti için kullanılırken bu çalışmada web kullanım davranışı saldırı tespitinde kullanılmıştır. Program davranışları yerine kullanım davranışları üzerine uygulanan kNN sınıflayıcı yardımı ile saldırı veya normal kullanım desenleri belirlenmiştir. Oturumlarda istenen web sayfalarının sıklıkları onların oturum içerisindeki sıraları yerine kullanıldı. Bu şekilde oturumun davranışı elde edilmeye çalışıldı. Web sayfaları bir kelime, oturumlarda bir doküman olarak sunularak verilere metin sınıflamada başarılı olan kNN algoritması uygulanmaya çalışıldı [4].
Program davranışlarının modellenmesi ile kullanıcı davranışlarının modellenmesi ve hatta oturumların modellenmesi konuları aynı etki alanı içerisinde bulunurlar. Bunların her üçü de rahatça en yakın k komşu algoritmasına uygulanabilirler. Dolayısıyla program davranışları ile ilgili çalışmalar diğer davranış modelleri içinde örneklik oluşturmaktadır.
İlk çalışma UC Davis'ten Ko ve arkadaşları tarafından yapılmıştır, Ko bu çalışmasında kural özellikli bir dil kullanarak imtiyazlı programlardan bazılarının amaç davranışlarını belirlemek için ilk öneriyi sundu (setuid root programları ve unix için daemonlar) [7]. Program çalışması esnasında belirlenen davranıştan farklılık gösterenler "misuse" olarak varsayıldı. Bu araştırma saldırı tespitinde program davranışının modellenebileceğini göstermiştir.
New Mexico üniversitesinden Forrest’in grubu ise saldırı tespiti için discriminator olarak çalışan, programlar tarafından yayılan sistem çağrılarının kısa dizilerinin kullanımını tanıttı [2]. Normal davranış, çalışan bir Unix prosesindeki sabit uzunluklu sistem çağrılarının kısa dizileri olarak tanımlandı ve bunlar bir veritabanında toplandı. Bu çalışmalar artificial imnune, rule learning, hidden markov models gibi sınıflama şemaları ile birlikte yerine getirilmektedir [8,9,10]. Ghosh ve diğerleri [11] 1998 yılında DARPA BSM denetleme verisi için sistem çağrıları ile program davranışını öğrenmek için yapay sinir ağları teknikleri üzerinde çalıştı. 150 den fazla program profili oluşturuldu. Her bir program bir yapay sinir ağı ile eğitildi ve anormallik tespiti için kullanıldı. Onların Elmann recurrent sinir ağları bütün saldırıların % 77,3 lük kısmını % 10 hata ile tespit etti.
Birçok araştırmacı bireysel program profilleri inşa etmeye odaklansa bile Asaka [10] diskriminant analiz tabanlı bir yöntemi kullandı.
Bütün çalışmalar sistem çağrılarının sırası ile sistem çağrılarının sıklıklarının bulunması arasındaki karşılaştırma şeklindedir [11].
Saldırı tespitini tanımlamak için, sistem veya ağ kaynaklarının münasebetsiz, hatalı veya normal olmayan kullanımlarının neler olduğunun bilinmesi bir ihtiyaçtır. Bu, organizasyonun güvenlik politikası olarak tanımlanır.
Basit olarak güvenlik politikası; bir sistem veya ağ üzerindeki kaynaklara izin verilip verilmediğinin tanımlanmasıdır.
Saldırı tespiti bilgisayar sisteminde meydana gelen olayları izler ve onları analiz eder.
Bir saldırı bir kaynağın güvenilirlik, bütünlük ve kullanılabilirlik özelliklerini ortadan kaldırmaya çalışan etkidir, bu saldırılar her zaman başarılı olmayabilir.
Bu yüzden Saldırı Tespiti tanımlanan güvenlik politikasına aykırı olan münasebetsiz bir saldırıyı tespit etme sanatıdır.
Saldırı Tespit Sistemi (STS), İnternet veya yerel ağdan gelebilecek, ağdaki sistemlere zarar verebilecek, çeşitli paket ve verilerden oluşan saldırıları fark etmek üzere tasarlanmış sistemlerdir. Temel amaçları saldırıyı tespit etmek ve bunu ilgili kişilere mail, kısa mesaj yoluyla iletmektir.
Bazen yanlış kullanım ve saldırı tespiti arasında bir ayrım yapılır. Saldırı terimi dışarıdan yapılan atakları açıklamak için kullanılır; yanlış kullanım ise daha çok dahili ağ kaynaklı atakları açıklamak için kullanılır. Saldırı tespiti iki tane analiz metoduna göre sınıflanabilir: anormallik ve yanlış kullanım tespiti.
Saldırganlar harici ve dahili olmak üzere iki tiptir. Harici saldırganlar ağın dışından atak yaparlar fakat dahili bir saldırgan daha önceden bildiği sistem üzerinde işlem yapar.
IDS tarafından false positive ve false negative olarak isimlendirilen iki tip hata oluşturulur.False positive hatası, ortada saldırı yokken IDS tarafından saldırı olduğu kararına varılması durumunda meydana gelir. Bir false negative hatası ise gerçekten bir saldırı olduğunda bunun saldırı olarak görülememesidir. Buna kaçak atak ismi de verilir.
Saldırı tespitinin bazı faydaları bulunmaktadır;
Saldırı engelleme için; tanıma ve doğrulama, güvenlik duvarları, şifreleme teknikleri, erişim kontrolü gibi yöntemler kullanılmakta olup bunlar tam anlamıyla yeterli olamamaktadır o yüzden saldırı tespitine ihtiyaç duyulmaktadır [5].
Saldırı tespit sistemlerini Gordeev[6] şu şekilde sınıflamaktadır.
Analiz Açısından
Kullanılan Bilgi Açısından
Reaksiyon Açısından
Analiz Zamanı Açısından
Mimari
Analiz Yaklaşımı
Bilgi Tabanlı Sınıflandırma
Tepki Tabanlı Yaklaşım
Analiz Zamanı Yaklaşımı
Mimari
Büyük miktardaki veri içerisinden anlamlı bilginin çıkarıldığı tekniğe veri madenciliği adı verilir. Veri madenciliği tekniğinin web verisine uygulanmasına ise web madenciliği adı verilmektedir. Web madenciliği temel olarak üç alt alana ayrılır.
Veri madenciliğinin alt alanlarından birisi olan web kullanım madenciliği web sunucu günlük verileri üzerinde çalışır. Bu çalışma sonucunda kullanıcı erişim desenleri yoluyla kullanıcı davranışları bulunur. Web kullanım madenciliği sayesinde bulunan kullanıcı davranışları saldırı tespitinde de etkin olarak kullanılabilmektedir. Saldırı tespiti için kullanılan veri web sunucu günlüklerindeki veriler olduğu için bu çalışma web kullanım madenciliğinin alanına girmektedir.
Elde bulunan oturum bilgileri üzerinde metin sınıflama işlemi yapmak için öncelikle her bir web sayfasının bir kelime, her bir oturumunda bir doküman olarak sunulacağı bilinmelidir. Web sayfalarının istek sırası yerine web sayfalarının istenme sıklıkları kullanılacaktır.
Metin sınıflamada eldeki dokümanlar vektörler şeklinde ifade edilir. Burada da elde bulunan oturum dosyaları sıklık veya tf*idf ağırlık tekniklerinden birisi ile vektörlere dönüştürülür. Yeni bir oturumun normal veya anormal olduğu ise kNN sınıflayıcı ile bulunur. KNN sınıflayıcı yeni oturum ile daha önceden eğitilmiş oturumlar arasındaki benzerliğe veya yakınlığa bakar, yakınlık k komşu derecesinde ise oturum normal, aksi halde anormal kabul edilir.
Metin sınıflama tekniğinin saldırı tespitine uygulanmasının en büyük avantajı saldırı tespitinde elde bulunan farklı durumların sayısının azlığıdır. Mesela bir web sitesinde ortalama olarak 100 civarında web sayfası bulunur halbuki ortalama bir doküman içerisinde 15000 kelime vardır.
Üzerinde saldırı tespiti yapılan veri, GYTE (Gebze Yüksek Teknoloji Enstitüsü) Kütüphanesi web sunucusu günlük dosyaları idi. Web sitesi üzerinde bulunan sayfaların sayısı ise toplam 100 civarında idi. Toplam 86 günlük eğitim verisi kullanıldı.
Bir oturumdaki veriler şu şekilde olabilmektedir
Oturum no:123
Oturum no:123 Default.asp Bilgiler.htm Ktarama.htm Tarama.asp Ktarama.htm Tarama.asp Veritabanlari.htm Ktarama.htm Kaynaklar.htm |
Elide 100 farklı web sayfası olduğu için dizi yüz elamanlı olacaktır. Önce sıklıklar bulunacak ve ardından bunlar bir ağırlık bulma yöntemi ile vektöre dönüştürülecektir.
Eğitim amaçlı seçilen oturum dosyalarından normal kullanım profilleri bulunur. Daha sonra bu profilden sapma gösterenler bulunmaya çalışılır. Bu şekilde normal kullanım profilinden sapma gösterenlerin anormal davranış gösterdikleri tespit edilir.
Saldırı tespitinde performansın ölçüsünü ROC (Receiver Operating Characteristic) değeri verir. Ve performans k değerine bağlıdır. Bu değer komşuluğun ölçüsünü vermektedir. Bu değer 5 gibi bir sayı olduğu zaman (k=5) normal olarak verilen bir noktaya en yakın beş noktanın da normal olarak kabul edileceği anlaşılır.
Anormallik tespiti için kullanılacak en yakın k komşu algoritmasının sözde kodları aşağıda verilmiştir.
 |
ayrıca eşik değerinin seçimi de önemli bir konudur. Yanlış seçilmesi durumunda hata oranı artmaktadır. Eşik değeri yüksek olduğu zaman bazı saldırılar normal davranış göstermekte ve tespit edilmeleri mümkün olamamaktadır.
A= aij şeklinde matris olarak verilebilir, aij, j numaralı dokümanda bulunan i numaralı kelimenin ağırlığıdır. aij hesabı için bazı yöntemler bulunur. fij, j dokümanı içerisinde i numaralı kelimenin meydana gelme sıklığını verir. N, bulunan doküman sayısını verir. M, birbirinden farklı olan kelimelerin sayısını vermektedir. nij ise bütün koleksiyondaki i numaralı kelimelerin meydana gelme sıklığını verir. En basit yaklaşım boolean ağırlık bulma yaklaşımıdır. Bu yaklaşımda eğer kelime doküman içerisinde kullanılmışsa 1 değerine set edilir diğer durumda 0 değerine set edilir. Diğer basit bir yaklaşım sıklık ağırlığı yöntemidir. Buna göre doküman içerisinde kelimelerin kaç kez tekrar ettiği bulunur.
aij=fij
Daha genel bir ağırlık bulma yöntemi ise tf*idf (term frequency inverse term frequency) olarak bilinir. Bu yaklaşımda bütün dokümanlardaki kelimelerin kullanım sıklıkları aşağıdaki gibi bulunur.
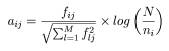
A matrisi için satırların sayısı dokümanların içerisindeki kelimelerin adedine bağlıdır. Bu kelimelerin adedi çok olduğu zaman azaltmak gerekir. Bu da özellik seçimi gibi bazı yöntemlerle yerine getirilir.
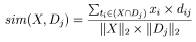
Burada X test dokümanıdır. Dj,j numaralı eğitim dokümanıdır. ti, X ve Dj tarafından paylaşılan bir kelimedir. Xi, X içerisindeki ti kelimesinin bulunma sayısı (ağırlığıdır). dij, Dj dokümanında bulunan ti kelimelerinin sıklığını verir.
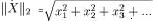
Saldırı tespiti yapmada davranış modellerinin kullanılması önemli avantajlar sağlamaktadır. Davranışları modellemek için bu çalışmada en yakın k komşu tabanlı yeni bir algoritma kullanılmıştır. Y. Liao tarafından sistem çağrılarına uygulanan algoritma burada web sayfa isteklerine uygulanmıştır. Yapılan saldırı tespiti çalışması metin sınıflama çalışmasına benzetilerek yapılmıştır. Metin sınıflamaya göre daha az nesne ile çalışıyor olması ise bu çalışmanın en büyük avantajı olmuştur.
|
|










